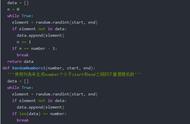
进行众数匹配
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
#得到聚类结果第i类的 True Flase 类型的index矩阵
mask = (clusters ==i)
#根据index矩阵,找出这些target中的众数,作为真实的label
labels[mask] = mode(digits.target[mask])[0]
#有了真实的指标,可以进行准确度计算
accuracy_score(digits.target, labels)
0.793544796883695110.4 聚类结果的混淆矩阵
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(digits.target, labels)
np.fill_diagonal(mat, 0)
sns.heatmap(mat.T, square=True, annot=True, fmt=‘d‘, cbar=False,
xticklabels=digits.target_names,
yticklabels=digits.target_names)
plt.xlabel(‘true label‘)
plt.ylabel(‘predicted label‘)

即将高纬的 非线性的数据
通过流形学习
投影到低维空间
from sklearn.manifold import TSNE
# 投影数据
# 此过程比较耗时
tsen = TSNE(n_components=2, init=‘pca‘, random_state=0)
digits_proj = tsen.fit_transform(digits.data)
#计算聚类的结果
kmeans = KMeans(n_clusters=10, random_state=0)
clusters = kmeans.fit_predict(digits_proj)
#将聚类结果和真实标签进行匹配
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
# 计算准确度
accuracy_score(digits.target, labels)11. 高斯混合模型(聚类、密度估计)
k-means算法的非概率性和仅根据到族中心的距离指派族的特征导致该算法性能低下
且k-means算法只对简单的,分离性能好的,并且是圆形分布的数据有比较好的效果
本例中所有代码的实现已上传至 git仓库
11.1 观察K-means算法的缺陷通过实例来观察K-means算法的缺陷
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
# 生成数据点
from sklearn.datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples=400, centers=4,
cluster_std=0.60, random_state=0)
X = X[:, ::-1] # flip axes for better plotting
# 绘制出kmeans聚类后的标签的结果
from sklearn.cluster import KMeans
kmeans = KMeans(4, random_state=0)
labels = kmeans.fit(X).predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap=‘viridis‘);
centers = kmeans.cluster_centers_
plt.scatter(centers[:,0], centers[:, 1], c=‘black‘, s=80, marker=‘x‘)

k-means算法相当于在每个族的中心放置了一个圆圈,(针对此处的二维数据来说)
半径是根据最远的点与族中心点的距离算出
下面用一个函数将这个聚类圆圈可视化
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
def plot_kmeans(kmeans, X, n_clusters=4, rseed=0, ax=None):
labels = kmeans.fit_predict(X)
# plot the input data
ax = ax or plt.gca()
ax.axis(‘equal‘)
ax.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap=‘viridis‘, zorder=2)
# plot the representation of the KMeans model
centers = kmeans.cluster_centers_
ax.scatter(centers[:,0], centers[:, 1], c=‘black‘, s=150, marker=‘x‘)
radii = [cdist(X[labels == i], [center]).max() for i, center in enumerate(centers)]
#用列表推导式求出每一个聚类中心 i = 0, 1, 2, 3在自己的所属族的距离的最大值
#labels == i 返回一个布尔型index,所以X[labels == i]只取出i这个族类的数据点
#求出这些数据点到聚类中心的距离cdist(X[labels == i], [center]) 再求最大值 .max()
for c, r in zip(centers, radii):
ax.add_patch(plt.Circle(c, r, fc=‘#CCCCCC‘, lw=3, alpha=0.5, zorder=1))
#如果数据点不是圆形分布的
k-means算法的聚类效果就会变差
rng = np.random.RandomState(13)
# 这里乘以一个2,2的矩阵,相当于在空间上执行旋转拉伸操作
X_stretched = np.dot(X, rng.randn(2, 2))
kmeans = KMeans(n_clusters=4, random_state=0)
plot_kmeans(kmeans, X_stretched)

高斯混合模型能够计算出每个数据点,属于每个族中心的概率大小
在默认参数设置的、数据简单可分的情况下,
GMM的分类效果与k-means基本相同
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=4).fit(X)
labels = gmm.predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap=‘viridis‘);
#gmm的中心点叫做 means_
centers = gmm.means_
plt.scatter(centers[:,0], centers[:, 1], c=‘black‘, s=80, marker=‘x‘);