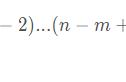现在,我们想要找到具有高影响力的用户。直观上来讲,Pagerank 会给拥有很多朋友的用户提供更高的分数,而这些用户的朋友反过来会拥有很多朋友。
pageranks = nx.pagerank(fb) print(pageranks) ------------------------------------------------------ {0: 0.006289602618466542, 1: 0.00023590202311540972, 2: 0.00020310565091694562, 3: 0.00022552359869430617, 4: 0.00023849264701222462, ........}
使用如下代码,我们可以获取排序后 PageRank 值,或者最具有影响力的用户:
import operator sorted_pagerank = sorted(pagerank.items(), key=operator.itemgetter(1),reverse = True) print(sorted_pagerank) ------------------------------------------------------ [(3437, 0.007614586844749603), (107, 0.006936420955866114), (1684, 0.0063671621383068295), (0, 0.006289602618466542), (1912, 0.0038769716008844974), (348, 0.0023480969727805783), (686, 0.0022193592598000193), (3980, 0.002170323579009993), (414, 0.0018002990470702262), (698, 0.0013171153138368807), (483, 0.0012974283300616082), (3830, 0.0011844348977671688), (376, 0.0009014073664792464), (2047, 0.000841029154597401), (56, 0.0008039024292749443), (25, 0.000800412660519768), (828, 0.0007886905420662135), (322, 0.0007867992190291396),......]
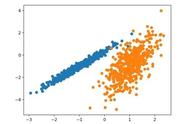
将含有最具影响力用户的子图进行可视化:
first_degree_connected_nodes = list(fb.neighbors(3437)) second_degree_connected_nodes = [] for x in first_degree_connected_nodes: second_degree_connected_nodes =list(fb.neighbors(x)) second_degree_connected_nodes.remove(3437) second_degree_connected_nodes = list(set(second_degree_connected_nodes)) subgraph_3437 = nx.subgraph(fb,first_degree_connected_nodes second_degree_connected_nodes) pos = nx.spring_layout(subgraph_3437) node_color = ['yellow' if v == 3437 else 'red' for v in subgraph_3437] node_size = [1000 if v == 3437 else 35 for v in subgraph_3437] plt.style.use('fivethirtyeight') plt.rcParams['figure.figsize'] = (20, 15) plt.axis('off') nx.draw_networkx(subgraph_3437, pos, with_labels = False, node_color=node_color,node_size=node_size ) plt.show()

黄色的节点代表最具影响力的用户
应用
Pagerank 可以估算任何网络中节点的重要性。
- 已被用于根据引文寻找最具影响力的论文
- 已被谷歌用于网页排名
- 它可以对推文进行排名,其中,用户和推文作为网络的节点。如果用户 A 跟随用户 B,则在用户之间创建连边;如果用户推文或者转发推文,则在用户和推文之间建立连边。
- 用于推荐系统
一些中心性度量的指标可以作为机器学习模型的特征,我们主要介绍其中的两个指标
- 介数中心性:拥有最多朋友的用户很重要,而起到桥梁作用、将一个领域和另一个领域进行连接的用户也很重要,因为这样可以让更多的用户看到不同领域的内容。介数中心性衡量了特定节点出现在两个其他节点之间最短路径集的次数。
- 度中心性:即节点的连接数。
代码
使用下面的代码可以计算子图的介数中心性:
pos = nx.spring_layout(subgraph_3437) betweennessCentrality = nx.betweenness_centrality(subgraph_3437,normalized=True, endpoints=True) node_size = [v * 10000 for v in betweennessCentrality.values()] plt.figure(figsize=(20,20)) nx.draw_networkx(subgraph_3437, pos=pos, with_labels=False, node_size=node_size ) plt.axis('off')

如上图所示,节点的尺寸大小和介数中心性的大小成正比。具有较高介数中心性的节点被认为是信息的传递者,移除任意高介数中心性的节点将会撕裂网络,将完整的图打碎成几个互不连通的子图。
应用
中心性度量的指标可以作为机器学习模型的特征。
总结在这篇文章中,我们介绍了了一些最有影响力的图算法。随着社交数据的出现,图网络分析可以帮助我们改进模型和创造价值,甚至更多地了解这个世界。
,