“入门”是良好的动机,但是可能作用缓慢。如果你手里或者脑子里有一个项目,那么实践起来你会被目标驱动,而不会像学习模块一样慢慢学习。

另外如果说知识体系里的每一个知识点是图里的点,依赖关系是边的话,那么这个图一定不是一个有向无环图。因为学习A的经验可以帮助你学习B。因此,你不需要学习怎么样“入门”,因为这样的“入门”点根本不存在!你需要学习的是怎么样做一个比较大的东西,在这个过程中,你会很快地学会需要学会的东西的。
当然,你可以争论说需要先懂python,不然怎么学会python做爬虫呢?但是事实上,你完全可以在做这个爬虫的过程中学习python,因为如果学会了python的基本语法,我认为入爬虫是很容易的。我写的第一个爬虫大概只需要10分钟,自学的 scrapyd , 看官方文档花了20分钟,因为我英文不是很好,很多单词需要搜索一下。
说说当初写的一个集群爬某瓣的经验吧。
首先你要明白爬虫怎样工作。
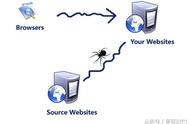
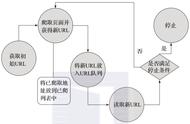
想象你是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页,这个叫initial pages,用$表示吧。
在人民日报的首页,你看到那个页面引向的各种链接。于是你很开心地从爬到了“国内新闻”那个页面。太好了,这样你就已经爬完了俩页面(首页和国内新闻)!暂且不用管爬下来的页面怎么处理的,你就想象你把这个页面完完整整抄成了个html放到了你身上。
突然你发现, 在国内新闻这个页面上,有一个链接链回“首页”。作为一只聪明的蜘蛛,你肯定知道你不用爬回去的吧,因为你已经看过了啊。所以,你需要用你的脑子,存下你已经看过的页面地址。这样,每次看到一个可能需要爬的新链接,你就先查查你脑子里是不是已经去过这个页面地址。如果去过,那就别去了。

好的,理论上如果所有的页面可以从initial page达到的话,那么可以证明你一定可以爬完所有的网页。
具体的实现源码由于平台限制没法全部发出来,你们可以后台私信我“源码”或者“爬虫”小编会一一分享给你们的
,