前言:网络爬虫技术顺应互联网时代的发展应运而生。目前网络爬虫的使用范围是比较广的,在不同的领域中都有使用,爬虫技术更是广泛地被应用于各种商业模式的开发。
一、什么是网络爬虫
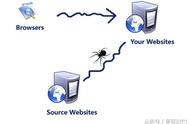
互联网是一个庞大的数据集合体,网络信息资源丰富且繁杂,如何在数据的海洋里找到自己需要的信息呢?网络爬虫技术顺应互联网时代的发展应运而生。网络爬虫,又称为网络蜘蛛,实际上音译 Spider 得到,此外 Crawler,bots, robots 以及 wanderer等都是其同义词。定义网络爬虫时,可从广义与狭义两个角度进行,从狭义角度看,该软件程序采取标准 http 协议对万维网信息空间的遍历依靠超链接与Web 文档检索办法完成;广义角度出发,网络爬虫是对 Web 文档进行检索依靠 http 协议就能够实现。

网络爬虫这一程序在网页的提取过程中表现出极强的功能,其在引擎中具有网页下载的功能,且在引擎中不可缺少。其实现某站点的访问主要是用设计好的程序,在设计者设计好规则的情况下对网站、小程序或者搜索引擎等进行数据的浏览和抓取,由此获得自己所需要的相关信息的集合的过程。网络爬虫的主要作用就是在海量的互联网信息中进行爬取,抓取有效信息并存储。在“数据为王”的时代,数据的搜集成为了各行各业必须掌握的本领,各显神通,谁搜集的数据越多越快越精准就成为在激流勇进的市场中站稳脚跟的法宝,网络爬虫技术是爬取数据的高效程序。
二、网络爬虫的应用
目前网络爬虫的使用范围是比较广的,在不同的领域中都有使用,爬虫技术更是广泛地被应用于各种商业模式的开发,数据抓取者对大量数据进行分析等加工再利用,推测出互联网用户的偏好,再顺势推送给与之匹配的用户群体。例如多家新闻资讯平台不生产产品,而是利用爬虫技术爬取别家的新闻资讯数据进行整合再利用。再如外卖平台,利用爬虫技术抓取外卖程序上的消费者点单数据,给客户优先推送某些经常消费的外卖店铺,从而提高客户粘度,并从外卖商家获取利润。网络爬虫技术已经成为大数据行业蓬勃发展必不可少的重要手段,谁掌握了数据,谁就占据了市场的优势地位。
三、国内外网络爬虫研究现状
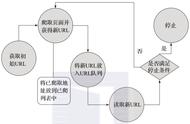
网络初始阶段,网络爬虫就存在,目前对网络爬虫的研究成果也是繁多的。最早的爬虫是 google 爬虫,该爬虫主要的功能包括针对各爬虫组件能够完成各异进程。维护单独 URL 服务器的过程中, URL 集合的下载则是必要的;网页的获取也能够由爬虫程序实现;在索引的进程中,能够对超链接以及关键字实现提取;进程的解决过程中,应该 URL 能实现相对路径向绝对路径的转换,上述各进程的通信主要是依靠文件系统。
网络爬虫中获取多个进程主要是依靠网络存档雇员完成的,在一次性进行彻底的爬行过程中,对应了64个hosts 。储存爬虫进程,主要在磁盘中,而储存来源则是非本地 URLs;爬行完成阶段中,通过大量的操作实现在各 host种子 sets 中加入 URLs。
目前,市场上普遍使用的引擎包括 google 和百度等,这些引擎的爬虫程序技术都是保密的。而市面上的爬虫实现策略主要有:广度优先、Repetitive、定义以及深层次爬行等多种爬虫程序。同时,估算 Web 页数量主要是以概率论为基础实现的,该抽样爬虫技术能够实现对互联网 Web 规模的评价;通过包括爬行深度以及页面导入链接等分析方法,能够有效的对由程序下载无关 Web 页等在内的选择性的爬行程序实现限制。
网络爬虫技术发展现状显示了,国际中google对 youtube的收购是投入极大成本的,而收购的目的在于对视频内容市场的获取。市场上众多的新兴公司对此业务范围也是有所涉及的, google的发展为楷模,就应该投入到搜索引擎中。
搜索引擎的未来趋势为由技术就能够掌握互联网,提供给各大网站索引功能,有效结合计算机提供的算法以及人力手工完成的辅助编辑,因此,用户得到的结构相关性更大,同时,也使人类发现数学公式的单纯使用是不能够达到理想效果的,在检索过程中不应忽视人类智慧的重要作用,因此,网络爬虫程序是市场所迫切需要的。
四、Robots协议与爬虫
Robots协议是网络爬虫技术这一行业内通用的规则,也称为网络爬虫协议,数据网站所有者可以在自己的网站设立一份协议,用来提醒利用网络爬虫技术访问和搜集数据的一方,什么数据可以爬,什么数据不能爬,或者设置防抓取的屏蔽措施,用来保护数据。
一般而言,技术人员在利用爬虫技术抓取信息时遵守站点的协议就不会产生侵权、不正当竞争或者刑事法律问题,但是,随着爬虫技术的不断发展,数据资源范围越来越广,“爬虫”可以到达的地方也越来越多。
在竞争激烈的市场环境下,利益驱使“爬虫”突破协议或者技术规则,抓取一些不能或者不该抓取的信息,侵犯其他商业主体的利益、公民的个人信息以及政府机关的保密信息,此时,就需要发挥法律的规制作用。除了在法律法规方面对网络爬虫的限制,我们也可以从技术层面去预防,风险画像就是比较成熟地解决网络爬虫爬取数据的手段之一。IP风险画像可以实时判定IP状态,采取打分机制,量化风险值,精准识别恶意动态IP(利用秒拨等黑产工具伪装成正常用户IP的黑产资源),解决由此带来的爬虫、撞库、薅羊毛等风险行为。
近几年,随着我国对个人隐私,公民信息数据泄露的逐渐重视,相关部门对爬虫案件的处理态度逐渐“严厉”。只有平衡数字经济与网络治理、数据保护之间的界限,才能更好地为我国网络发展和数字经济的发展保驾护航。
,