在互联网时代中,我们正被数据包围,我们是网络数据生产者和使用者。日常中在互联网上许多行为产生了数据,例如淘宝、阅读记录等。
由此互联网存在海量数据,当下互联网是了解市场、分析竞争者、获取更多销售资料最 优的手段,所以数据收集和分析成为推动业务发展的关键能力。面对海量数据如何挑选分析变成一个较大难题,互联网爬虫就可以很好的实现这一过程。今日小编为大家讲解网络爬虫的种类和抓取工作的相关的资讯。
一、互联网爬虫的定义
互联网爬虫指的是参考已有的规则,主动获取万维信息的程序或者脚本,还有其他俗称,自动索引、蚂蚁、网页蜘蛛、网络机器人、网页追逐者等。
互联网爬虫利用互联网中网站服务器的内容运行,属于一种程序或者脚本。工作时是主动从互联网中搜索信息或者数据。读取并抓取所需要页面的某些信息,最 后处理完成全部能正常打开的页面。当下出现常见的数据采集APP都是根据互联网爬虫的功能或原理。
二、互联网爬虫的价值
在大数据的今天,互联网爬虫提供给企业可以用于数据分析,帮助企业得到用户行为、自身产品劣势、竞争者资料等信息。
互联网爬虫的价值和数据价值相等同,现在,掌握大量有用的数据,等于拥有决策的主动权。网络爬虫的可以应用很多方面比如
1)抓取各大销售平台的销量情况及用户点评来进行分析。
2)分析大众点评、美团网等餐饮类网站的用户消费、评价和发展趋势。
3)分析各个城市中学区房的比例,以及学区房比普通二手房价格高出多少。
三、互联网爬虫工作原理
互联网爬虫组成模块大致可以分初链接库、网络抓取模块、网页处理模块、网页分析模块、DNS模块、待抓取链接队列、网页库等,这些模块可形成循坏体系,就可以循环分析和抓取。
爬虫工作原理:第 一步确定目标信息网,第二步进行抓取页面模块,第三步进行页面分析模块,最 后一步数据存储模块。
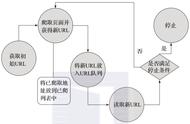
四、爬虫工作基本流程:
选择互联网中部分链接地址作为种子URL;
把种子URL放在待抓取的URL队列中,爬虫对URL队列按照顺序读取;
将URL通过DNS解析;
把链接地址转换为网站服务器对应的IP地址;
网页下载器通过网站服务器对网页进行下载;
下载的网页为网页文档形式;
对网页文档中的URL进行抽取;
过滤掉已经抓取的URL;
没有抓取的URL再循环抓取,当URL队列为空时停。
爬虫技术的种类,主要分为四种:聚焦网络爬虫、通用网络爬虫、增量式网络爬虫、DeepWeb爬虫。更多类型详细解读可以查看百度。