图片来源:视觉中国
侯宏/文炙手可热的生成式AI或大模型,将如何影响商业史走向?一个可能的思考角度是:大模型的入局将影响整个数字化生产力的分工结构。据此,本文提出大数据时代向大智能时代嬗变的论断,包括以下三方面命题:首先,大模型的本质是智能的大规模集中供给,是智能的基础设施化;其次,这一趋势推动数据与智能的解耦,使得没有大数据的企业也可接入高质量智能;最后,由此带来的智能红利对中小企业尤为有利,或成为经济结构性增长的重要来源。以上挑战了大数据时代的思维范式,为相关人士理解数字化变局提供了一个有趣的思考起点。
大模型的本质
是智能的大规模集中供给
生成式AI在诸多方面不同于传统AI。一方面,顾名思义,生成式AI擅长生成新内容,而传统AI局限于解释现有数据或者做出预测。投资机构a16z的MartinCasado认为:“微芯片将计算的边际成本降到了零,互联网将分发的边际成本降到了零,大模型则将创作的边际成本降到零。”另一方面,基于自然语言的人机交互界面,生成式AI具备了技术民主化的特质。正如麦肯锡的LareinaLee所说:“用户不需要任何数据科学或机器学习专业知识,就能有效地利用生成式AI完成工作。这就好比大型机只有技术专家才会使用,而个人电脑人人皆可掌握。”
然而,本文强调生成式AI灵活应对多种非预设任务的能力,区别于需根据预设任务进行专门设计的传统AI。要理解这一点,不妨考虑传统AI公司面临的商业模式困境。以AI四小龙为代表的“传统”AI公司尽管技术投入巨大,但难以摆脱为企业客户提供定制服务的低扩展性模式。这是因为,要实现AI算法与特定任务情景的匹配,技术供应方不得不提供大量低自动化程度的工程服务,既拉低利润率又降低可扩展性。相比之下,体验过的人士不难认同,大模型好似百科全书,几乎所有领域都应对自如。尽管在专业领域需要模型“微调”,但正如“微调”二字所暗示的,其定制化程度远低于传统AI项目,预示着更好的经济性。
能力通用性和其他两个经济属性一起,成就了大模型的基础设施地位。一方面,大模型具备规模经济。众所周知,极度昂贵的训练成本,是大模型为通用性所付出的代价。其规模经济性体现在,模型参数规模超越某临界值后,其智能表现随参数规模增长呈非线性增长。作为这一规律的提出者和坚定信仰者,OpenAI在扩大模型参数规模的路上蒙眼狂奔。另一方面,大模型具备生成性(generativity)。大模型提供者自身并不能充分发挥其价值,但其上可以“长出”各类面向真实用例的应用以实现难以预估的长尾价值。
大模型的本质是智能的集中化供给。作为基础设施,“集中供给”并不新鲜,新鲜的是“智能的集中供给”。我们需要区分基础设施的智能化和智能的基础设施化。智能手机、智能网络、智能城市、智能电网等词汇描述的是给定基础设施的智能化,指对异质性基础设施(手机、网络、城市、电网等)规模经济的个性化调度和外部性的多样化开发。智能的基础设施化则是指智能的生产和供给本身具备了基础设施属性。
智能似乎天然与某个聪明的、不可复制的、充满创意的大脑相关,怎么可能基础设施化呢?如果它真的基础设施化了,又意味着什么呢?尽管这似乎是人类历史上第一次,但历史告诉我们,每次基础设施集中化过程都深刻地影响当时的生产力与生产关系。正如电力的集中化生产和大规模供给推动了第二次工业革命,智能的大规模集中供给有望把数字化时代推向新高潮。
大模型推动数据与智能的解耦
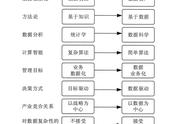
笔者把这个新高潮命名为“大智能时代”,以区别于大数据时代。大数据时代,投资人通常问一家公司,你有数据吗?即便有人意识到有数据的公司不一定能捕获其价值,但几乎所有人都认为没有数据一定不能够从智能中获益。以这种数据-智能紧耦合为底色的商业思维深刻地影响着商业实践。相关概念包括曾鸣教授提出的“数据智能”、脱胎自亚马逊飞轮效应的“数据飞轮”以及移植自平台经济学的“数据网络效应”。
这些概念通常都会援引Google作为案例。Google经常被美国的反垄断机构约谈,一个原因是所谓的数据网络效应:搜索引擎的市场份额越大,用户数据就越多,而数据训练出来的机器算法就越来越智能,进而进一步提升其用户体验,导致更大的市场份额。曾鸣教授更是基于阿里巴巴的类似经验,提炼出以“数据智能”为基石的“智能商业”方法论。
Google首席经济学家HalVarian则认为,Google的地位不是来自数据资源本身,而应归功于其卓越的数据科学与工程能力更好地释放了数据资源的价值。能力优势和数据网络效应都能带来竞争优势和份额,但前者是稀缺性创造的李嘉图租,后者是市场地位创造的垄断租。他的潜台词是,你不能培养出卓越能力是你的事儿,不要给我扣垄断的帽子。不少人或嗤之以鼻,认为是Hal屁股决定脑袋。但OpenAI的异军突起表明,他可能是对的。ChatGPT对Google搜索的挑战并不依靠数据优势。GPT3.0之前的所有训练数据都来公开数据,但不妨碍OpenAI在大模型能力方面走在Google前面,威胁到其搜索业务。
真正重要的不是OpenAI比Google厉害,而是它这么厉害还能对外开放,而非像Google那样独家用于自家服务。当然,这方面更厉害的是Meta(即Facebook),开源了模型的参数且免费支持商用。大模型好似中央电厂,它持续提炼几乎人类的所有知识(数据),然后对大众输出,使得智能不需要在低水平重复开发。这挑战了大数据时代“无数据,不智能”的圭臬——企业的智能商业不一定以自身数据整合为前提。基于大模型的底层参数,企业只需要小数据去微调这个模型,便有可能开展“智能商业”。
值得强调的是,“数据与智能的解耦”并不意味着数据不重要,而意味着数据重要性在产业不同环节并非均匀分布。数据作为智能原料的地位无可撼动。变化在于,大模型使用这种原料上的效率远超其他,以至于有志于“智能商业”的企业构建自身数据飞轮可能丧失经济性。数据飞轮或者数据网络效应的逻辑仍然成立,但问题是:当所有企业都试图转起自己的数据飞轮,凭什么是你脱颖而出呢?国家电网能够稳定输出电力时,为什么要在工厂旁边自建一个小发电厂呢?当然可能存在备份或补充的需要,但那是另一个逻辑。
释放智能红利,驱动经济结构性增长
数据与智能解耦带来的经济性被我称为智能红利。Martin所强调的创造内容边际成本为0是消费者侧的红利。比较一下传统的内容创造过程和基于生成式AI的内容创造过程,便不难理解。然而,经济发展主要靠企业生产率的提升。智能红利在这方面体现在:企业原本需要精心构建、维护自身数据供应链才能实现 “智能商业”所需的“数据智能”,而智能大规模的集中供给可能大大节省这一过程所需的投资、时间、精力,使得企业可以专注于业务创新。
上述智能红利是促进数字经济结构性增长的利器。中国经济发展面临诸多挑战,而其持续增长的一个潜在来源是挖掘区域、行业发展不均背后的结构性潜力。众所周知,小微企业受制于较为落后的IT基础设施、孱弱的数据基础和有限的预算,数字化转型进程落后于大中型企业。那么,要实现数字经济结构性增长,有必要思考如何弥补上述企业侧的数字化鸿沟。
相对于其他数字化技术,生成式AI在实现这一目标方面得天独厚。一方面,生成式AI应用对企业自身的数字化准备程度要求相对较低。如果消费者都能使用,有什么理由小微企业不能呢?另一方面,在采纳生成式AI应用方面,小微企业具有“光脚的不怕穿鞋的”优势。诸多阻碍大中型企业采纳生成式AI的因素(如数据泄密)可能对小微企业影响甚微。并且,大中型企业需要解决新旧IT之间融合的问题,小微企业也没有这方面的负担。总之,智能红利不是大中型企业的专属,而是小微企业能够站在同一智能起跑线上的历史性机遇。
接入生成式AI应用有两种方式。一是企业首先微调出自己独有的大模型,然后在私有或混合环境下为自身各类应用赋能;二是直接利用现有的大模型提供商的API(如基于GPT)开发生成式AI应用,供自己使用或者作为服务售卖给客户。两者都受益于智能的集中供给,但小微企业更可能通过后者获取智能红利,其中也蕴含着应用开发者的创业机遇。
结语
生成式AI和大模型的诞生纯属偶然。它好似从天而降的陨石,蛮不讲理地改变了原有产业格局和历史脉络。笔者作为数字化产业的参与者、观察者和研究者,勾勒了改变发生的一种可能。按照这一逻辑往下推演,可以得到对当下一些热门话题的不同观点,留待后续。
(作者系北京大学国家发展研究院助理教授)
,