图1-31 神经网络的分类
我们可以使用对比学习法来分析机器学习和人类学习,两者进行对比,总会有强弱,我们可以使用强的那个来补弱的那个,也就是以强补弱。机器学习发展迅速,逻辑和方法清晰,很多方面已经超过了人类学习。比如在现代的围棋中,很多棋手都是和机器进行对弈训练,学习机器的方法,然后再和人类进行比赛。所以有的棋手认为现在的围棋就是背机器棋谱。
在无监督学习中,没有老师,神经元进行自学。输入数据没有被标记,也没有确定的结果。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类,clustering)试图使类内差距最小化,类间差距最大化。一句话就是:给定数据,寻找隐藏的结构。无监督学习和人类自学有点类似,没有老师告诉你什么是正确的,而你只是自己来找不同。有点像不会英文的人一直在看英文资料,虽然不知道讲了什么,但是能发现一些词组的固定搭配,句式等等(如图1-32所示)。

图1-32 无监督学习方框图和示例
在有监督的学习中,也就是有老师,这个老师指的是给学习系统的数据都是有标签的。然后训练学习系统,学习系统进行输出,然后老师会告诉学习系统偏差在哪,学习系统按照偏差进行修正。一句话:给定数据,预测标签。有监督的学习和人类的教学类似,老师教给学生知识,学生有错误老师进行指正,然后学生改正错误而进步。有点像我们用中英文对照的文章学习英文,看的文章多了,学会了英文,然后也能看懂别的英文文章(如图1-33所示)。

图1-33 有监督学习方框图和示例
强化学习是介于无监督学习和有监督学习之间的一种方法,有一个老师,他不会告诉你哪里做错了,只是在给你的行为打分,做得好分数高。一句话:给定数据,学习如何选择一系列行动,以最大化长期收益。比如你和别人在网上下棋,没人告诉你怎么走能赢,而你就在不断试错,如果你最后赢了,就能赢得奖励,这样通过试错,你下棋的能力提高了。阿拉法狗就是通过强化学习进行训练(如图1-34所示)。

图1-34 强化方框图和示例
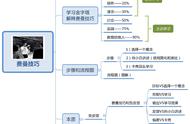
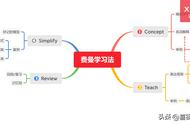
费曼技巧的学习和神经网络的强化学习有点类似,介于有老师学习和无老师学习之间。费曼技巧中的你如同强化学习中的学习系统,小白如同环境。你给小白讲述如同对环境的动作,而是否卡壳是反馈的状态,奖赏则是你不卡壳的满足感(如图1-35所示)。