一般在做SQL优化的时候讲究使用exists带替代IN的做法,理由是EXISTS执行效率要比IN高。

个人理解:
IN表示范围,指某一字段在某一范围之内,这个范围一般使用子查询来获取,由此可知IN子查询返回的结果应该就是这个范围集。
EXISTS表示存在,指至少存在一处,这个条件由EXISTS子查询来完成,但是在这里EXISTS子查询返回的结果却不再是一个结果集,而是一个布尔值(true或false),其实这个挺好理解的,EXISTS就表示如果子查询能查到值则返回true,则执行EXISTS之前的语句。
测试数据
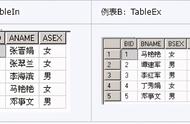
员工参数课程培训数据,两次不同课程培训分别存在CLASS_A 和 CLASS_B 两张表中。
CLASS_A:

CLASS_B:

需求:查找同时参加了两门课程的员工。
两种方式实现
下面分别使用in 和 exists两种方式实现。
1、in 方式查询
SELECT * FROM class_a WHERE id IN ( SELECT id FROM class_b);
2、exists 方式查询
SELECT * FROM class_a A WHERE EXISTS ( SELECT * FROM class_b B WHERE A.id = B.id );
说明:
上述两种方法查询结果一样,但exists 方式速度要快。分析如下:
1)如果连接列id 上有索引,那么查询CLASS_B时,无需查询实际表,仅需要查索引就可以了。
2)使用exists ,那么只有查到一行数据满足条件就会终止查询,不会产生临时表。
3)使用in查询时,数据库首先会执行子查询,然后将结果保存在临时表中,然后扫描整个临时表,很多情况下非常耗费资源。
如何用exists来代替in
假如有一个表user,它有两个字段id和name,要查询名字中带a的用户信息:
最简单的SQL:select * from user where name like '%a%'; 使用IN的SQL:select u.* from user u where u.id in (select uu.id from user uu where uu.name like '%a%');
将使用IN的SQL修改为使用EXISTS的SQL该怎么写呢?
一开始我直接将u.id in 替换为EXISTS,获得如下语句 :
select u.* from user u where exists(select uu.id from user uu where uu.name like '%a%');
经过测试发现输出结果错误,该语句将所有的用户全部一个不漏的查询出来了,相信你也发现了问题,后来我对上述语句做了修改如下:
select u.* from user u where exists (select uu.id from user uu where uu.name like '%a%' and uu.id=u.id);
只是在子查询中添加了“and uu.id=u.id”,结果查询结果正确。
总结:EXISTS子查询可以看成是一个独立的查询系统,只为了获取真假逻辑值,EXISTS子查询与外查询查询的表是两个完全独立的毫无关系的表(当第二个表中的name中有包含a的姓名存在,那么就执行在第一个表中查询所有用户的操作),当我们在子查询中添加了id关联之后,EXISTS子查询与外查询查询的表就统一了,是二者组合组建的虚表,是同一个表(这样当子查询查询到虚表中当前行的uu.name中包含a时,则将虚表当前行中对应的u.id与u.name查询到了)
所以一切的重点就在这个ID关联之上,添加ID关联,数据库会先将两张表通过ID关联组合成一张虚表,所有的查询操作都在这张虚表上完成,操作的是同一张表,当然就不会出现之前的那种情况了!
总结
exists 方式查询 比 in 方式查询效率高,但in 可读性较好。建议尽可能使用exists方式,避免使用子查询,除非in 的参数为数值列表。
后面会分享更多DBA方面内容,感兴趣的朋友可以关注下!