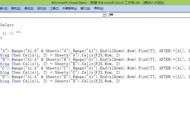
- m_main 模块包含整个主流程逻辑,入口方法 main
- 类模块 D_ArrayVar 与 D_GVar ,是为了做到 数据源的列位置变化,也不需要修改程序
- D_Person 与 D_Sku ,分别表示销售员与货品,里面有关键的累计逻辑
- 模块 Msys_Function 与类模块 C_GetFile ,是很久以前写的帮助类
如果你是 vba 的高级用户,可能会觉得直接使用 字典 数组 的方式即可完成,但注意,直接 字典 数组 方式会导致代码难以维护

上面说的 vba 方案,我大概花费了接近1小时的时间(vba 中编写类模块太繁琐了),期间有一个需求变动,得益于面向对象的优点,在几分钟内完成应对,并且无需要大范围做测试。
但是,这样的需求如果在 Python 中,我们的处理效率可以提高多少呢?我使用 Python 的 pandas 包处理,在5分钟内搞定,并且代码有非常好的阅读性与扩展性。
这次我们直接使用 pandas 读写 excel 数据,而无需使用 xlwings 库
首先定义需要的列与每列的统计方式:

- 其中核心是 g_agg_funcs 字典,他定义了每个输出列的统计方法。凡是文本类型的内容,统一用 first ,就是去组内的第一笔
接着定义加载 excel 数据到 DataFrame:

- 由于数据源的标题在第3行,因此在调用 read_excel 时,参数 header 设置为 None,表示不需要用 excel 中的数据行作为 DataFrame 的标题
- header=df.iloc[header_idx,:] ,把指定行的内容读取出来
- df.columns=header ,赋值作为 df 的标题
- df.dropna(subset=[g_pName]) ,把名字列中是空的行去掉
然后即可生成结果,如下: