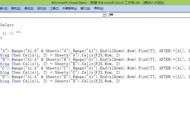
- df.groupby(cols).agg(g_agg_funcs) ,按销售员与货品分组并统计结果,pandas 中就是这么简单
但是,我们需要每个销售员单独一个 sheet 输出结果。如下图:

- with pd.ExcelWriter('result.xlsx') as exl: ,由于本案例需要对一个 excel 文件进行批量输出,因此不能直接使用 DataFrame.to_excel 。这里先创建一个 ExcelWriter对象
- res.index.get_level_values(0) ,从分组结果中获得销售人员列,但这里的输出是带重复值的,因此我们需要使用 set 去重复
- res.loc[idx,:] ,通过一个销售人员,即可获得这个销售员的货品汇总结果(是一个 DataFrame),这时就可以调用 to_excel 输出结果
- to_excel 中的参数 startrow ,表示结果输出在第2行
到这里,你可能会问,还有一个按照货品的汇总结果啊,这是非常简单,因为汇总方式是一样的,只是汇总字段有变化而已。如下:

- 这里特意重复写一次 ExcelWriter ,我们这次是往已经存在的 excel 文件追加数据,因此其参数 mode='a' ,是 append 的意思。而要使用追加模式,需要使用 openpyxl 引擎,因此需要设置 engine='openpyxl'

在完成代码的情况下,如果需要在汇总结果中新增一列对单价列求平均,在 Python 的方案中,只需要在定义 g_agg_funcs 中添加单价列的统计方式,如下: