毕竟大模型运行在自己的电脑上,那么训练数据就直接存在电脑里,肯定会比上传到云端再让服务器去计算来得安心一点,更省去了各种伦理道德云端审核的部分。
不过,目前想要在自己的电脑上搭建本地大模型其实并不是一件容易的事情。
较高的设备要求是原因之一,毕竟本地大模型需要把整个运算过程和负载全部都放在自家的电脑上,不仅会占用你的电脑机能,更会使其长时间在中高负载下运行。
其次嘛……
从Github/Huggingface上琳琅满目的项目望去,要达成这一目标,基本都需要有编程经验的,最起码你要进行很多运行库安装后,在控制台执行一些命令行和配置才可以。

别笑,这对基数庞大的网友来说可真不容易。
那么有没有什么比较「一键式」的,只要设置运行就可以开始对话的本地应用呢?
还真有,Koboldcpp。
工具用得好,小白也能搞定本地大模型简单介绍一下,Koboldcpp是一个基于GGML/GGUF模型的推理框架,和llama.cpp的底层相同,均采用了纯C/C 代码,无需任何额外依赖库,甚至可以直接通过CPU来推理运行。

(图源:PygmalionAI Wiki)
当然,那样的运行速度会非常缓慢就是了。
要使用Koboldcpp,需要前往Github下载自己所需的应用版本。
当然,我也会把相对应的度盘链接放出来,方便各位自取。
目前Koboldcpp有三个版本。
koboldcpp_cuda12:目前最理想的版本,只要有张GTX 750以上的显卡就可以用,模型推理速度最快。
koboldcpp_rocm:适用于AMD显卡的版本,基于AMD ROCm开放式软件栈,同规格下推理耗时约为N卡版本的3倍-5倍。
koboldcpp_nocuda:仅用CPU进行推理的版本,功能十分精简,即便如此同规格下推理耗时仍为N卡版本的10倍以上。

(图源:Github)
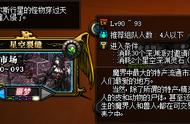
打开软件后,首先可以关注一下Presets选项。
软件首页的Presets里,分为旧版N卡、新版N卡、A卡、英特尔显卡等多种不同模式的选择。
默认情况下,不设置任何参数启动将仅使用CPU的OpenBLAS进行快速处理和推理,运行速度肯定是很慢的。
作为N卡用户,我选用CuBLAS,该功能仅适用于Nvidia GPU,可以看到我的笔记本显卡已经被识别了出来。