介绍两种最为常用的相关系数:皮尔逊person相关系数和斯皮尔曼spearman等等级相关系数。他们可以用来衡量两个变量之间的相关性的大小,根据数据满足不同的条件,我们要选择不同的相关系数进行计算和分析。(建模论文中最容易用错的方法)
1、总体和样本总体——所要考察对象的全部个体叫做总体.
我们总是希望得到总体数据的一些特征(例如均值方差等)
样本——从总体中所抽取的一部分个体叫做总体的一个样本.
计算这些抽取的样本的统计量来估计总体的统计量:
例如使用样本均值、样本标准差来估计总体的均值(平均水平)和总体的标准差(偏离程度)。 例子: 我国10年进行一-次的人口普查得到的数据就是总体数据。 大家自己在QQ群发问卷叫同学帮忙填写得到的数据就是样本数据。
2、总体皮尔逊Person相关系数回顾《概率论与数理统计》中的数理统计部分: 如果两组数据和是总体数据(例如普查结果)
那么总体均值:
总体协方差:
直观理解协方差:如果X、Y变化方向相同,即当X大于(小于)其均值时,Y也大于(小于)其均值,在这两种情况下,乘积为正。如果X、Y的变化方向一直保持相同,则协方差为正;同理,如果X、 Y变化方向一直相反,则协方差为负;如果X、Y变化方向之间相互无规律,即分子中有的项为正,有的项为负,那么累加后正负抵消。
注意:假设X,Y变化方向一直相同,说明它们存在很强的正相关或负相关,但是协方差的大小和两个变量的量纲有关,因此不适合做比较。
总体皮尔逊相关系数就是在总体协方差的基础上消去量纲的影响
2.1 总体皮尔逊相关系数计算如果两组数据和是总体数据(例如普查结果)
那么总体均值:
总体协方差:
所以,定义总体皮尔逊Person相关系数为:
其中,就是对X、Y的标准差
我们知道就是用来标准化数据的,因此皮尔逊相关系数可以看作是剔除了两个变量量纲的影响,即X和Y标准化之后的协方差。
而且可以证明
3、样本皮尔逊Person相关系数如果两组数据和是样本数据(例如调查得到的数据)
那么样本均值:
样本协方差:
所以,定义样本皮尔逊Person相关系数为:
其中,就是对X、Y的样本标准差
4、相关性可视化
从图中我们可以看出,散点图为一条直线,即y与x的关系可以描述为y=kx b,相关性为1或-1,而越小于1的绝对值,相关性1越不显著,散点图越离散
实际上皮尔逊相关系数反应的是线性系数
5、关于皮尔逊相关系数的理解误区
上面四个图的皮尔逊相关系数均为0.816
但是,可以发现第二幅图(横向)明显是一个抛物线的这种相关性,直线很难刻画它,第三幅图出现了一个异常值,离散于其他的点,假如去掉这个离群点,相关系数可能会更大,因为其他的点还是服从于这条直线的;第四幅图也出现了一个异常值,但是这个异常值对整体结果影响特别大,假如去掉这个异常值,x和y之间的相关系数应该是0。
也就是说异常值对皮尔逊相关系数的影响是很大的,我们也不能单纯靠皮尔逊相关系数来理解数据。
再来看一张图,冰激凌销售量和气温之间的关系

冰激凌销售量和气温之间的关系
这个数据计算出来的皮尔逊相关系数为0,但我们不能说x和y之间没有关系,它们大致是服从于一个抛物线的。
因此这里需要特别注意:
- 这里的相关系数只是用来衡量两个变量线性相关程度的指标;
- 也就是说,你必须先确认这两个变量是线性相关的,然后这个相关系数才能告诉你他俩相关程度如何。
(1)因此得先画散点图,说明这两个变量之间是线性的,说明有线性关系
(2)然后再来计算皮尔逊相关系数来刻画相关程度
5.1总结:(1)非线性相关也会导致线性相关系数很大
(2)离群点对相关系数的影响很大,
(3)如果两个变量的相关系数很大也不能说明两者相关,可能是受到了异常值的影响。
(4)相关系数计算结果为0,只能说不是线性相关,但说不定会有更复杂的相关关系(非线性相关)。
5.2再来强调一下:(1) 如果两个变量本身就是线性的关系,那么皮尔逊相关系数绝对值大的就是相关性强,小的就是相关性弱;
(2)在不确定两个变量是什么关系的情况下,即使算出皮尔逊相关系数,发现很大,也不能说明那两个变量线性相关,甚至不能说他们相关,我们一定要画出散点图来看才行。
6、对相关系数大小的解释相关性 | 负 | 正数 |
无相关性 | -0.09~0.0 | 0.0~0.09 |
弱相关性 | -0.3~0.1 | 0.1~0.3 |
中相关性 | -0.5~0.3 | 0.3~0.5 |
强相关性 | -0.5~1 | 0.5~1 |
上表所定的标准是主观性和不严格的,对相关系数的解释是依赖于具体的应用背景和目的的。上表只做参考
事实上,比起相关系数的大小,我们更加关注的是显著性(假设检验)
7.描述性统计计算系数之前需要做一些描述性统计,如下

matlab常用描述性统计函数
对各列数据计算一一些统计量,一般使用上面加粗的那几个
可以将下面的描述性统计表格放到论文中:
身高 | 体重 | 肺活量 | 50米跑 | 立定跳远 | 坐位体前屈 | |
最小值 | 135 | 16 | 1450 | 7.8 | 52 | 0.5 |
最大值 | 171 | 65 | 3272 | 15 | 205 | 17.5 |
均值 | 156.0033841 | 46.78341794 | 2333.233503 | 10.79201354 | 166.8257191 | 9.496615905 |
中位数 | 157 | 47 | 2391 | 10.7 | 167 | 9.6 |
偏度 | -0.295393671 | -0.360686808 | -0.285228204 | 0.709545507 | -0.836873414 | -0.224969278 |
峰度 | 2.742704116 | 9.43558535 | 2.751974067 | 3.299413754 | 8.431328913 | 2.755030069 |
标准差 | 7.389409879 | 5.031473399 | 350.4361539 | 1.310872852 | 16.81358657 | 2.938186121 |
借助假设检验,我们对相关系数进行显著性检验:
- 第一步:提出原假设H0和备择假设H1 (两个假设是截然相反的哦)
假设我们计算出了一个皮尔逊相关系数r,我们]想检验它是否显著的异于0.那么我们可以这样设定原假设和备择假设: H0:r = 0,H1:r≠0
- 第二步:在原假设成立的条件下,利用我们要检验的量构造出一个符合某个分布的统计量
(注1:统计量相当于我们要检验的量的一个函数,里面不能有其他的随机变量) (注2:这里的分布一般有四种:标准正态分布、t分布、分布和F分布)
对于皮尔逊和关系数r而言,在满足一定条件下,我们可以构造统计量:(言外之意就是首先要进行条件检验)
其中n就是样本量,是一个常量,这个分布是自由度为n-2的标准正态分布
- 第三步:将我们要检验的这个值带入这个统计量中,可以得到一个特定的值(检验值)。
- 假设我们现在计算出来的相关系数为0.5,样本为30,那么我们可以得到
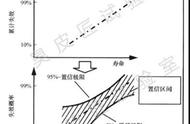
- 第四步:由于我们知道统计量的分布情况,因此我们可以画出该分布的概率密度函数pdf,并给定一个置信水平,根据这个置信水平查表找到临界值,并画出检验统计量的接受域和拒绝域。
例如,我们知道上述统计量服从自由度为28的t分布,其概率密度函数图形如下:

自由度为28的t分布概率密度函数图形
代码:
x = -4:0.4:4;
y = tpdf(x, 28);
plot(x,y,'-')
grid on % 加上网格线
- 第四步:由于我们知道统计量的分布情况,因此我们可以画出该分布的概率密度函数pdf,并给定一个置信水平,根据这个置信水平查表找到临界值,并画出检验统计量的接受域和拒绝域。
常见的置信水平有三个:90%, 95%和99%, 其中95%是三者中最为常用的。
因为我们这里是双侧检验,所以我们需要找出能覆盖0.95概率的部分
t分布表: https://wenku.baidu.com/view/d94dbd116bd97f192279e94a.html,这个表里的是单侧检验,所以我们需要找到概率为0.975,自由度为28的临界值
查表可知,对应的临界值为2.048,因此我们可以做出接受域和拒绝域。
- 第五步:看我们计算出来的检验值是落在了拒绝域还是接受域,并下结论。因为我们得到的t* = 3.05505 > 2.048,因此我们可以下结论:在95%的置信水平上,我们拒绝原假设H0:r = 0,因此r是显著的不为0的。
在第四步需要去查表,其实我们还有一种不需要查表的方法:P值判断法:
- P值判断法
- 刚刚的例子是双侧检验,所以对于P值的计算和单侧检验略有不同:
P_value = (1 - tcdf(3.05505, 28))*2 % 双侧检验P值 最终计算结果为 0.0049
% P_value = 1 - tcdf(3.05505, 28) 单侧检验P值
- P值 = 0.0049<0.05,即在95%的置信水平上拒绝原假设
- 在本例中,拒绝原假设就表示显著的异于0.
p<0.01,在99%的置信水平上拒绝原假设 | p>0.01,在99%的置信水平上无法拒绝原假设 |
p<0.05,在95%的置信水平上拒绝原假设 | p>0.05,在95%的置信水平上无法拒绝原假设 |
p<0.10,在90%的置信水平上拒绝原假设 | p>0.10,在90%的置信水平上无法拒绝原假设 |
补充:代表什么意思?(显著性标记)
0.5就代表不显著
0.5^*就代表在90%的置信水平上显著(也就是拒绝原假设),依次类推
0.1~0.05之间*,0.05-0.01之间**,<0.01***
***P<0.01,**P<0.05,*P<0.10
9、皮尔逊相关系数假设检验的条件- 第一,实验数据通常假设是成对的来自于正态分布的总体。因为我们在求皮尔逊相关性系数以后,通常还会用t检验之类的方法来进行皮尔逊相关性系数检验,而t检验是基于数据呈正态分布的假设的。
- 第二,实验数据之间的差距不能太大。皮尔逊相关性系数受异常值的影响比较大。
- 第三:每组样本之间是独立抽样的。构造t统计量时需要用到。
因此,数据来自于正态分布是需要验证的,而后两个条件是默认满足的。
那么又该如何检验数据是否是正态分布?
10、检验数据是否是正态分布10.1 JB检验 大样本n>30雅克-贝拉检验(Jarque -Bera test)
对于一个随机变量,假设其偏度为S,峰度为K,那么我们可以构造JB统计量:
可以证明,如果\{X_i\}是正态分布,那么在大样本情况下JB~( 自由度为2的卡方分布)
注:正态分布的偏度为0,峰度为3
那么进行假设检验的步骤如下:
- H0:该随机变量服从正态分,H1:该随机变量不服从正态分布
- 然后计算该变量的偏度和峰度,得到检验值JB*,并计算出其对应的p值
- 将p值与0.05比较,如果小于0.05则可拒绝原假设,否则我们不能拒绝原假设。
偏度和峰度

matlab实现JB检验:
MATLAB中进行JB检验的语法: [h,p] = jbtest(x,alpha) 当输出h等于1时,表示拒绝原假设(不满足正态分布); h等于0则代表不能拒绝原假设(满足正态分布)。
alpha就是显著性水平,一般取0.05,此时置信水平为1-0.05=0.95
x就是我们要检验的随机变量,注意这里的x只能是向量。
10.2 Shapiro-wilk检验 小样本检验步骤:
- H0:该随机变量服从正态分,H1:该随机变量不服从正态分布
- 然后计算威尔克统计量,并计算出其对应的p值
- 将p值与0.05比较,如果小于0.05则可拒绝原假设,否则我们不能拒绝原假设
在统计学中,Q-Q图(Q代表 分位数Quantile)是一种通过比较两个概率分布的分位数对这两个概率分布进行比较的概率图方法。
首先选定分位数的对应概率区间集合,在此概率区间上,点(x,y)对应于第一个分布的一个分位数x和第二个分布在和x相同概率区间上相同的分位数。
这里,我们选择正态分布和要检验的随机变量,并对其做出Q-Q图,可想而知,如果要检验的随机变量是正态分布,那么Q-Q图就是一条直线。
要利用Q-Q图鉴别样本数据是否近似于正态分布,只需看Q-Q图上的点是否近似地在一条直线附近。(要求数据量非常大,远大于30)
,