在接触机器学习、训练模型、数据挖据、OCR这些领域,都会碰到一个词“置信度”,究竟是什么意思呢?
我们只学习最简单好记的几个点:
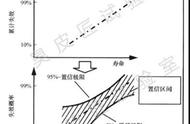
1、这是一个统计学的词,英文confidence coefficient,相关的还有一个词叫置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。
2、置信度越高,说明对输出的结果越肯定。
3、置信度衡量的是规则准确率如何,即符合给定条件(即规则的“前提”语句所表示的前提条件)的所有规则里,跟当前规则结论一致的比例有多大。计算方法为首先统计当前规则的出现次数,再用它来除以条件(“前提”语句)相同的规则数量。
4、看了很多文章,我觉得以下这个例子最好懂:
你扔了14次的钢镚,有8次正面朝上,6次背面朝上,你有多大的把握说钢镚不均匀,正面朝上的概率更大,这个把握就是置信度。
如果14次有8次正面朝上,我们是否敢说这个“钢镚铸造有偏差”呢?
这里面有两种可能,其一是偏差确实存在。另一个原因是,它就是偶然造成的。那么这两种情况的可能性各是多大呢?从数学上可以算出,前者的可能性是57%,后者是43%。也就是说,钢镚铸造有偏差这件事有可能是真的,但是我们不太确定。我们把自己有多么确定这件事也量化地衡量一下,它就是置信度。
具体到这个问题,置信度是57%,当然相反的结论“这个钢镚没有铸造问题”的置信度是43%,在统计上,我们一般认为,置信度不到95%的结论不大能相信。
那么怎么才能够提高置信度呢?通常的办法就是要增加所统计的样本的数量。
如果一直保持8:6这个正反面的比例,我们扔得次数越多,最后就越有把握说,“钢镚两面不均匀”。根据T-测试原理的计算公式可以得知,大概扔140次就能说置信度达到95%了。当然如果扔到几千次, 我们的置信度就能达到99%。也就是说,扔了140次以后,我们有95%的把握说,这个钢镚两面不匀,它造成了80:60的偏差。而运气的因素,只占剩下的5%。(这个例子的作者:姜地主链接:https://www.jianshu.com/p/a15796489b5b
来源:简书)
5、在OCR的应用中,置信度可以来判断识别的准确性,当训练OCR这样的机器学习算法时,需要知道所使用的最佳参数和特征,以及如何修正项目中出现的分类、识别和检测错误。在笔云的AI应用实践中,类似集装箱门和电费单识别这样的数据标本已经达到10万级的数量,也就是置信区间足够大,可以提供一个非常准确的置信度判断。
,