众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕。不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列。通过分析弹幕,我们可以快速洞察广大观众对于视频的看法。
阿喵通过一个关于《八佰》的视频弹幕数据,绘制了如下词云图,感觉效果还是可以的。

点击并拖拽以移动
这里多说一句,小编是一名python开发工程师,这里有我自己整理的一套最新的python系统学习教程,包括从基础的python脚本到web开发、爬虫、数据分析、数据可视化、机器学习等。想要这些资料的可以关注小编,并在后台私信小编:“01”即可领取。
海量的弹幕数据不仅可以绘制此类词云图,还可以调用百度AI进行情感分析。那么,我们该如何获取弹幕数据呢?本文运用Python爬取B站视频、腾讯视频、芒果TV和爱奇艺视频等弹幕,让你轻松获取主流视频网站弹幕数据。
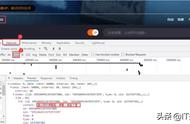
一、B站视频弹幕1.网页分析本文以爬取up主硬核的半佛仙人发布的《你知道奶茶加盟到底有多坑人吗?》视频弹幕为例,首先通过以下步骤找到存放弹幕的真实url。

点击并拖拽以移动
简单分析url参数,很显然,date参数表示发送弹幕的时间,其他参数均无变化。因此,只需要改变date参数,然后通过beautifulsoup解析到弹幕数据即可。
2.爬虫实战
import requests #请求网页数据
from bs4 import BeautifulSoup #美味汤解析数据
import pandas as pd
import time
from tqdm import trange #获取爬取速度
def get_bilibili_url (start, end) :
url_list = []
date_list = [i for i in pd.date_range(start, end).strftime( '%Y-%m-%d' )]
for date in date_list:
url = f"api.bilibili.com/x/v2/dm/his… {date} "
url_list.append(url)
return url_list
def get_bilibili_danmu (url_list) :
headers = {
"user-agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36" ,
"cookie" : "你自己的" #Headers中copy即可
}
file = open( "bilibili_danmu.txt" , 'w' )
for i in trange(len(url_list)):
url = url_list[i]
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text)
data = soup.find_all( "d" )
danmu = [data[i].text for i in range(len(data))]
for items in danmu:
file.write(items)
file.write( "\n" )
time.sleep( 3 )
file.close()
if name == "main" :
start = '9/24/2020' #设置爬取弹幕的起始日
end = '9/26/2020' #设置爬取弹幕的终止日
url_list = get_bilibili_url(start, end)
get_bilibili_danmu(url_list)
print(
"弹幕爬取完成"
)
3.数据预览

点击并拖拽以移动
二、腾讯视频弹幕1.网页分析本文以爬取《脱口秀大会 第3季》最后一期视频弹幕为例,首先通过以下步骤找到存放弹幕的真实url。