介绍 vivo 数据库备份恢复功能的演化,以及对备份文件的功能扩展。
一、概述
vivo互联网领域拥有的数据库组件分别为 MySQL、MongoDB、TiDB 等,其中MySQL集群占比绝大部分, MongoDB 集群占比小部分, TiDB 集群占比更小。为了介绍方便,本文把改造前的数据库备份恢复系统称为旧备份恢复系统,改造后的数据库备份恢复系统称为新备份恢复系统。我们将从旧的架构系统开始,发现其不足,慢慢的优化形成新的系统架构。
二、旧备份恢复系统
旧备份恢复系统架构图

旧备份恢复系统是基于Python 语言开发的,使用分布式文件系统GlusterFS,Python作为开发语言,使用任务调度模块Celery下发备份和恢复任务。或许由于之前开发时间紧迫,在服务可用性和Redis组件高可用性上,并未做过多的工作。若出现物理机宕机或网络等问题,将直接影响备份系统的稳定性。
2.1 备份模块
备份模块是旧备份恢复系统的一个主要功能服务,主要用于MySQL、TiDB、MongoDB 组件的备份调度、备份等任务,来完成每日的数据库备份。旧备份恢复系统主要使用的是逻辑备份,在仅有5台物理机上负责备份任务的发起和执行,由于互联网的体量大,数据库全备一次需要2天的时间,因此备份的成功率是按照2天统计。由于文件系统的高负载,以及备份中锁等原因也会出现备份调度失败的情况,导致整个物理机上的实例不能再次发起备份,需要手工维护才能继续备份,系统维护上也非常麻烦。
2.2 组件备份介绍
MySQL和TiDB的备份
【备份工具】:Mydumper Xtrabackup(MySQL)
【备份方式】:逻辑备份 物理机备份
逻辑备份 Mydumper 工具
Mydumper 是一款社区开源的逻辑备份工具。该工具主要由 C 语言编写,目前由 MySQL 、Facebook 等公司人员开发维护。
参考官方介绍,Mydumper 主要有以下几点特性:
- 支持多线程导出数据,速度更快。
- 支持一致性备份。
- 支持将导出文件压缩,节约空间。
- 支持多线程恢复。
- 支持以守护进程模式工作,定时快照和连续二进制日志。
- 支持按照指定大小将备份文件切割。
- 数据与建表语句分离。
Mydumper的主要工作步骤:
- 主线程 flush tables with read lock, 施加全局只读锁,以阻止dml语句写入,保证数据的一致性。
- 读取当前时间点的二进制日志文件名和日志写入的位置并记录在metadata文件中,以供恢复使用。
- start transaction with consistent snapshot; 开启读一致事务。
- 启用n个(线程数可以指定,默认是4)dump线程导出表和表结构。
- 备份非事务类型的表。
- 主线程 unlock tables,备份完成非事务类型的表之后,释放全局只读锁。
- 基于事务dump innodb tables。
- 事务结束。
基于Mydumper 以上的特性,PingCAP公司针对 TiDB 的特性进行了优化,Mydumper 包含在 tidb-enterprise-tools 安装包中。对于 TiDB 可以设置 tidb_snapshot 的值指定备份数据的时间点,从而保证备份的一致性,而不是通过 FLUSH TABLES WITH READ LOCK 来保证备份一致性。使用 TiDB 的隐藏列 _tidb_rowid 优化了单表内数据的并发导出性能。TiDB 官方早起提供了Mydumper备份工具,后期提供了BR 物理机备份工具,然而物理机备份受限制于文件系统,在GlusterFS 文件系统下,只能使用Mydumper 做逻辑备份。
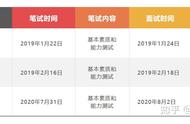
Mydumper 备份属于逻辑备份,需要读全表,因此备份效率会低很多。同一个数据库,在文件系统不变的情况下,逻辑备份和物理备份的对比。

从该统计可以看出,逻辑备份时间很不稳定,Mydumper 备份最短一次是6.5个小时,最长在23小时,而物理机备份时间基本维持在7个小时左右。
物理机备份Xtrabackup工具
Xtrabackup是Percona团队开发的用于MySQL数据库物理热备份的开源备份工具,具有备份速度快、支持备份数据压缩、自动校验备份数据、支持流式输出、备份过程中几乎不影响业务等特点,是目前各个云厂商普遍使用的MySQL备份工具。
由于物理机备份未使用压缩和打包,备份的文件受限于表的大小,在备份特别大的表时,总会出现文件系统分布不均匀的情况,大部分磁盘在80%的时候,某些磁盘的使用容量却超过95%,需要经常登录文件系统删除备份文件来消除告警。另外物理备份配置比例较小,备份占比不高。后续虽然经过一些了优化(增加打包和文件分拆功能),解决了磁盘分布不均的问题。但备份成功率提升不明显。
MongoDB 备份
【备份工具】:mongodbdump
【备份方式】:逻辑备份
【备份时间】:全天时间段
mongodbdump 是MongoDB 官方提供的备份程序,对于小于100G以内的备份还能轻松应付,但对于大于100G的实例虽然也能备份,不过备份时间会比较长。vivo目前有几十个大于1T的实例,备份难度可想而知,备份成功率很低。有些MongoDB 实例因为太大,导致从未成功过。2天的备份成功率基本在20%左右,哪怕统计一周的成功率也无法达到40%,大于1T的MongoDB 实例,因为文件系统过慢,总是出现备份一半就出现失败,虽经过多次优化,哪怕是把备份盘放置本地盘,再拷贝至文件系统,虽然备份成功率有所提高,但成功率依旧很差,而且还需要经常手工维护。
2.3 恢复模块
恢复模块也是基于Python开发,由Celery 模块调度恢复策略,根据已配置的数据库备份方式,选择相应的逻辑和物理机恢复。
逻辑恢复是直接使用备份文件对目标库进行恢复,不过逻辑恢复很慢,之前做过一次上T的数据库恢复,竟然恢复了1天左右的时间。不过逻辑备份也是有好处的,在恢复单个表时,可以直接把该表的文件系统拷贝出来,直接使用myloader程序直接恢复,可以非常快速的恢复单表,这比物理机恢复单个表要快很多。不过这里的恢复需要手工操作,代码并未实现该项功能。。
物理机恢复是直接使用文件系统挂载的方式,直接把文件系统挂载至目标机器,把备份的文件拷贝纸目标机器来恢复数据,功能相对简单一些,由于是直接拷贝文件,恢复速度相对会快一些。
恢复模块仅用于增加从库实例和延迟从库,未做到任一时间点的恢复,功能相对单一。
2.4 文件系统
GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。当客户端访问GlusterFS存储时,首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地还是在远程服务器上。读写操作将会被交给VFS(Virtual File System)来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client的计算,并最终经过网络将请求或数据发送到GlusterFS Server上。
vivo的备份模块使用的GlusterFS 文件系统,分别在两个区域的机房中。其中A机房是用于数据库备份和恢复,B机房主要用于异地灾备,增加备份文件的安全性。

A机房的文件系统主要挂载至备份恢复的主控机上,并且A机房文件系统也会挂载到需要物理备份的物理机上。数据库的物理机任何DBA人员均可登录,只要登录该机器上,便可以操作任一备份文件,这对于备份文件是十分危险的;由于A机房是单机房,存在单机房故障的可能,基于以上两点,B机房就应运而生了。
B机房的文件系统只挂载至备份恢复机器的主控机上,并且把A机房的备份文件拷贝至B机房,同时管控备份恢复的主控机权限,便可以确保备份文件系统的安全性。基于此,备份恢复主控机及B机房物理机权限只有2个人有权限访问,从而确保备份文件的安全性。
2.5 copy 模块
Copy 模块主要用于备份文件的拷贝,让备份文件保留2份副本,防止因A机房宕机,误删等情况下,导致备份文件的缺失。
A机房的文件系统用于数据库直接备份,B机房的文件系统中的数据,是由A机房通过Copy程序拷贝过来,在B机房保留一份副本。由于A机房承接备份和恢复两大功能,而且还要应用于拷贝文件至B机房,还要定时删除过期的备份文件,由此可知A机房的文件系统压力将有多大,这也是直接导致Copy程序效率将有多差,最终结果是B机房的文件要远远落后A机房,导致B机房异地备份名存实亡,Copy模块也变得形同虚设。
2.6 旧备份恢复系统存在问题
1. 效率不足
MySQL 两天才能完成一次全备份,而且恢复实例时间也比较长,不能满足日常恢复实例的时间要求。
MongoDB 大容量数据库比较多,而且逻辑备份已经无法应付现在的场景,超过50%以上的MongoDB集群已无法成功备份。
2. 旧功能不足
旧备份恢复系统目前只有 备份模块、恢复模块、Copy模块,功能单一,已经不能满足互联网领域的快速发展。
备份系统是Python代码完成的,最初开发未考虑高可用,逻辑复杂,维护困难。
3. 文件系统方面
① 文件系统权限控制较弱,不能达到安全要求
- A机房文件系统会有多处挂载,导致备份文件安全无法得到保障
② 文件系统压力较大,文件系统已经不堪重负
③ 异地灾备形同虚设
- 受文件系统读写的限制,异地灾备的文件系统存储的都是几天之前的备份文件
三、新备份恢复系统
基于Python开发的旧备份恢复系统存在许多缺点,最后引入Java 开发人员和对象存储,对备份系统进行全方位的改造,经过一系列改进,互联网领域目前的备份系统架构图如下: