预测模型在各个领域都越来越火,今天的分享和之前的临床预测模型背景上有些不同,但方法思路上都是一样的,多了解各个领域的方法应用,视野才不会被局限。
今天试图再用一个实例给到大家一个统一的预测模型的做法框架(R中同样的操作可以有多种多样的实现方法,框架统一尤其重要,不是简单的我做出来就行)。而是要:
数据划分eliminate syntactical differences between many of the functions for building and predicting models
通常我们的数据是有限的,所以首先第一步就是决定如何使用我们的数据,就这一步来讲都有很多流派。
数据比较少的情况下,一般还是将全部数据都拿来做训练,尽可能使得模型的代表性强一点,但是随之而来的问题就是没有样本外验证。上文写机器学习的时候提到,样本外验证是模型评估的重要一步,所以一般还是会划分数据。个人意见:好多同学就200多个数据,就别去划分数据集了,全用吧,保证下模型效度。
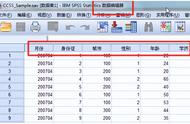
我现在手上有数据如下:

这是一个有4335个观测1579个变量的数据集,我现在要对其切分为训练集和测试集,代码如下:
inTrain <- createDataPartition(mutagen, p = 3/4, list = FALSE)
trainDescr <- descr[inTrain,]
testDescr <- descr[-inTrain,]
trainClass <- mutagen[inTrain]
testClass <- mutagen[-inTrain]
代码的重点在createDataPartition,这个函数的p参数指的是训练集的比例,此处意味着75%的数据用来训练模型,剩下的25%的数据用来验证。使用这个函数的时候要注意一定是用结局作为划分的依据,比如说我现在做一个死亡预测模型,一定要在生存状态这个变量上进行划分,比如原来数据中死亡与否的占比是7:3,这样我们能保证划分出的训练集死亡与否的占比依然是7:3。
数据划分中会有两个常见的问题:一是zero-variance predictor的问题,二是multicollinearity的问题。
第一个问题指的是很多的变量只有一个取值,不提供信息,比如变量A可以取y和n,y占90%n占10%,划分数据后训练集中有可能全是y,此时这个变量就没法用了。为了避免这个问题我们首先应该排除数据集中本身就是单一取值的变量,还有哪些本身比例失衡的变量,可以用到nearZeroVar函数找后进行删除。
第二个问题是共线性,解决方法一个是取主成分降维后重新跑,另一个是做相关,相关系数大于某个界值后删掉,可以用到findCorrelation函数。
下面的代码就实现了去除zero-variance predictor和相关系数大于0.9的变量:
isZV <- apply(trainDescr, 2, function(u) length(unique(u)) == 1)
trainDescr <- trainDescr[, !isZV]
testDescr <- testDescr[, !isZV]
descrCorr <- cor(trainDescr)
highCorr <- findCorrelation(descrCorr, 0.90)
trainDescr <- trainDescr[, -highCorr]
testDescr <- testDescr[, -highCorr]
ncol(trainDescr)
运行上面的代码之后我们的预测因子就从1575个降低到了640个。
接下来对于模型特定的预测算法,比如partial least squares, neural networks and support vector machines,都是需要我们将数值型变量中心化或标准化的,这个时候我们需要对数据进行预处理,需要用到preProcess函数,具体代码如下:
xTrans <- preProcess(trainDescr)
trainDescr <- predict(xTrans, trainDescr)
testDescr <- predict(xTrans, testDescr)
在preProcess函数中,可以通过method参数很方便地对训练数据进行插补,中心化,标准化或者取主成分等等操作,我愿称其为最强数据预处理函数。
建模与调参建模是用train函数进行的,caret提供的预测模型建立的统一框架的精髓也在train函数中,我们想要用各种各样的机器学习算法去做预测模型,就只需要在train中改动method参数即可,并且我们能用的算法也非常多,列举部分如下:

另外一个值得注意的参数就是trControl,这个参数可以用来设定交叉验证的方法:
trControl which specifies the resampling scheme, that is, how cross-validation should be performed to find the best values of the tuning parameters

比如我现在需要训练一个logistics模型(大家用的最多的),我就可以写出如下代码:
default_glm_mod = train(
form = default ~ .,
data = default_trn,
trControl = trainControl(method = "cv", number = 5),
method = "glm",
family = "binomial"
)
在上面的代码中,我们设定了4个重要的参数:
一是模型公式form,二是数据来源data,三是交叉验证方法,这儿我们使用的是5折交叉验证,四是模型算法method。
我现在要训练一个支持向量机模型,代码如下:
bootControl <- trainControl(number = 200)
svmFit <- train(
trainDescr, trainClass,
method = "svmRadial",
trControl = bootControl,
scaled = FALSE)
上面的代码运行需要一点时间,我们是用自助抽样法,抽样迭代次数200次,也就是抽200个数据集,所以比较耗时。
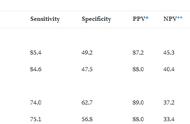
支持向量机是有两个超参的sigma和C,上面的结果输出中每一行代表一种超参组合,通过上图我们可以看到不同的超参组合下模型的表现