53 个量子比特的量子计算机“悬铃木”(Sycamore)。图片来源:参考文献 [1]
为了实现“量子优越性”,早在 2019 年 10 月,谷歌的量子计算团队就针对“量子随机线路采样”的运算任务,率先在该公司研发的 53 个量子比特的量子计算机“悬铃木”上进行 20 次循环运算,共计 100 万次采样,所需运算时长只有 200 秒,最终运算结果的保真度为 0.224%(数值越低,精度越高)。而如果采用当年运算速度最快的经典超级计算机 Summit 来计算得到同样的结果,则需耗费约 1 万年。
因此,谷歌的量子计算团队宣称率先实现了“量子优越性”。值得一提的是,量子计算机“悬铃木”的量子门精度已经达到很高的水准,其中单量子比特门和双量子比特门的精度分别达到了 99.84% 和 99.38%,探测精度也达到了 96.2%(关于量子比特门,将在下文进行解释)。
时任谷歌公司 CEO 的桑达尔·皮查伊(Sundar Pichai)也激动地表示:尽管量子计算机只是在某个特定的问题求解上展现出超过经典计算机的能力,但是这就像莱特兄弟首次成功试飞的飞机一样,在量子计算的发展历史上具有里程碑式的意义。
然而,很快就有众多的科研团体和研究机构质疑谷歌公司的研究成果。谷歌公司宣称的“量子优越性”,成了量子计算机的“虚晃一枪”。
经典计算的反击
我甚至比你算得更快!
其实,“量子随机线路采样”的运算任务并没有那么神秘。简单来说,该问题就是从一个量子门的集合中随机挑选单量子比特门作用到量子比特上,而在每个单量子比特门之间又会夹杂一层双量子比特门。
这里所说的“量子比特门”是用于在量子比特上执行特定的运算操作,这就类似于经典计算中的逻辑门,它们可以改变量子比特的状态,并允许我们对量子信息进行操控和处理。
其中,常见的量子比特门包括单量子比特门和双量子比特门。单量子比特门用于操作单个量子比特,例如改变其状态。而双量子比特门则用于操作两个量子比特,例如实现量子比特之间的相互作用和纠缠。通过组合不同的量子比特门操作,可以构建更复杂的量子电路,用于执行特定的量子计算任务。
“量子随机线路采样”的运算任务就像我们小时候常吃的夹心饼干一样,单/双量子比特门层层堆叠,从而在多次重复运算后测量最终的量子比特的状态(也就是完成了一次采样)。

随机量子线路采样示意图。图片来源:参考文献 [1]
而谷歌团队选择该运算任务的初衷也比较简单:
其一,众多的理论学者已经证明“量子随机线路采样”的运算任务在经典计算机上相当困难;
其二,该运算任务十分适用于他们开发的量子计算机“悬铃木”。
但是,IBM 公司质疑了谷歌团队的这一成果。这是因为,如果采用更加高效的数据存储和优化运算,就可以大大压缩采用经典超级计算机 Summit 完成“量子随机线路采样”任务的时间,仅仅需要 2.5 天!
除此之外,中国科学院理论物理研究所的张潘团队也质疑了这一成果。他们提出了一种新的模拟方法,极大地降低了运算复杂度,并且仅仅采用了 512 块 Tesla V100 32GB 显存 GPU,就可以在 15 个小时内完成该问题的求解。而如果采用更为强大的经典超级计算机,甚至可以将所需的运算时间缩短至几十秒。

中国科学院理论物理研究所的张潘团队的优化算法。图片来源:参考文献 [2]
也就是说,经典超级计算机在经过硬件升级和算法优化后,所需的运算时间甚至可以短于量子计算机“悬铃木”。这意味着,经典计算的反击卓有成效,并且在运算时间这一指标上推翻了之前谷歌宣称的“量子优越性”。
量子计算的再进化
是时候展现真正的力量了
其实,“量子优越性”本身就是新生的量子计算和成熟的经典计算之间的竞争,这是一种良性的竞争。
一方面,随着量子计算机量子比特数目的不断增加,以及自身运算错误率的不断降低,量子计算机终将在某些特定的运算任务上展现出巨大的潜力;另一方面,量子计算机的发展也进一步促进人们对于经典计算的优化和资源整合,从而不断提高经典计算机的算法效率和工程规模。
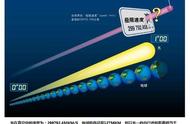
这次,谷歌的量子计算团队重整旗鼓,将原本只有 53 个量子比特的“悬铃木”量子计算机,进一步升级为具有 70 个量子比特的第二代量子计算机。这次,他们带着再进化的升级版量子计算机向经典计算机发起了新一轮的挑战。

“随机电路采样”中的相变问题的运算结果。图片来源:参考文献 [3]
这次谷歌团队选择的是“随机电路采样”中的相变问题(可以简单理解为是 2019 年“量子随机线路采样”任务的升级版),他们发表的论文宣称,采用新一代的量子计算机可以瞬时完成运算任务,而如果使用最新的排名第一的超级计算机 Frontier 则需要 47.2 年。