序言:
对于任何一家从事信贷业务的机构而言,展业就是拒绝所有的坏客群,让全部的好人进件。但很明显这个是一个伪命题。因为我们不可能拒绝所有的坏人,也不可能打包票说我们放贷的都是好人。好与坏,本来就是一个相对的概念。并且拒绝坏人是有成本的,每流失一位客人都是有成本的损失,俗称获客成本。拒绝人多了市场的同事也就不干了。而且拒绝的人因为没有实际的逾期表现,更多的是基于历史的数据表现而定义的坏人,其实我们无法实际验证他们真的就是坏,这属于幸存者偏差。
而且目前获客成本日益高涨的当前,在贷前做好客群捞回放松策略,或者在风险相比新客更低的贷中捞回优质老客并且经营,在这样场景中通过规则优化相关的策略手段调整,改变客群质量的影响,就显得非常重要了。
为此,番茄风控输出此系列文章,我们将从新客跟老客中拒绝捞回的方方面面跟大家讲解,过程中覆盖贷前、贷中环节,以及风控决策流中拒绝捞回的过程。
此外在知识星球中更会手把手讲解具体的实操内容,包括数据展示(excel)、数据案例跟代码(python),基本一看就懂,一跑就会。
因为完整内容较长,本次整体的内容将分成六大部分跟大家介绍,整体目录如下:
part1.拒绝捞回的概念,目的,使用场景
Part 2.拒绝捞回的方法
PART 3.捞回在决策流中的应用
PART 4.拒绝捞回的监控
PART 5.拒绝捞回的总结和思考
PART 6. 实操环节--拒绝推断(外推法)
PART 1.拒绝捞回的概念,目的,使用场景
拒绝捞回是指从风控拒绝的用户中,根据某些条件筛选出一部分用户予以通过。我们都知道经过风控的层层筛选后,拒绝样本中的坏人比例是比通过样本要高的,但是风控无法完美的区分好人和坏人,拒绝样本中也有一定比例的好人,如果把里面相对优质的人挑出来,使其通过风控,就可以促进放款量的上升,提升公司的业绩。需要注意的是拒绝捞回本身是一种风险下探的操作,虽然能提高放款量,但会造成一部分的坏账损失,所以关键在于怎么做好风险和收益的平衡,介绍的方法在循环贷和非循环贷产品上都适用。
关于拒绝捞回的使用场景有以下几个:
1)新客授信环节,为了提高授信通过率,促进拉新,会采取捞回的手段。
2)新客支用环节,增加新客放款量,以及提高新客到老客的转化率。
3)老客支用环节,这是捞回最常用的场景,随着最近获客成本上升,越来越多的机构更加注重老客的经营,并且老客的风险相比新客更低,捞回意义更大。
4)流失用户召回,对于那些一直被拒导致流失的用户,可以通过线下捞回手段筛选出 质量较优的一部分人,通过运营手段进行唤醒,并且对这些人群的风控做放松处理。
PART 2.拒绝捞回的方法
拒绝捞回简单来说就是对部分风控规则进行放松,这就涉及到两个问题,一是如何选择可以放松的规则,二是怎么对放松的用户做风险判断,来确保捞回后的整体坏账表现是在风险可接受范围内的。
可从以下几个方面来衡量一条规则的放松价值:
1)拒绝率,拒绝率越高,这条规则在决策中占的权重就越大,放松的空间也越大。
2)规则的软硬程度,硬规则指的是那些严拒规则,例如黑名单,欺诈规则等,命中这些规则的用户风险很高,是不可放松的。软规则指的是可根据风险容忍度调整的规则,常见的有多头共债规则,模型分规则等,这些规则对风险有一定的排序性,调整范围也大。
3)规则的线上效果,可对上述的软规则做回溯效果分析,重点看规则对于拒绝阈值尾部的排序能力以及精准度,对于尾部精准度差的规则可进行放松,如果规则本身排序能力变的很差,则可以做下线处理。下面举两个例子说明:

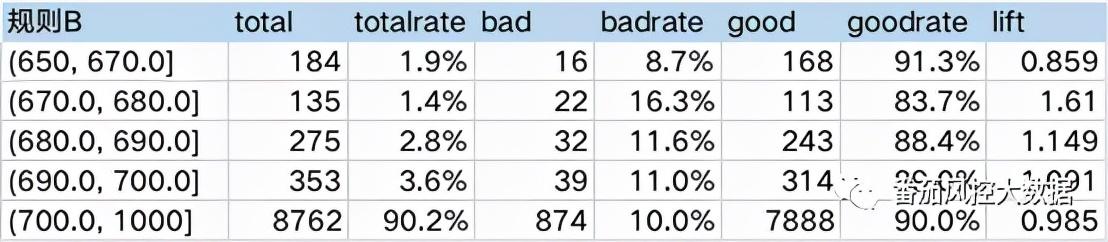
注:lift(提升度),其含义为经过某种排序后圈出来的坏用户占比,相对于随机抽样坏用户占比的提升。假设有100个人,其中10个为坏用户,将其随机分为5组,则理想情况下每组坏用户为2个,每组的badrate为2/20=10%,等于整体的badrate。现在有一个模型对这100个进行打分排序,选出分数最低的20个人,其中坏用户为4个,则badrate为4/20=20%,,lift = 20%/10% = 2,说明分数最低的一组能比随机分组多挑出2倍的坏用户。从这可以看出lift=1时,排序分组的badrate等于随机分组,说明对好坏没区分能力。lift<1时值越小,好用户概率越大,lift>1时值越大,坏用户概率越大。
规则A是一条多头规则,对通过的样本做了效果分析,可以看到每个箱体的lift 都接近等于1,这说明规则基本没有排序能力了,近乎失效了,这种规则就可以考虑下线掉,起到对风控的放松。
规则B是一条模型分规则(分数越高,风险越低),起初定的阈值是<=650,可看到>670时,lift呈单调性,排序能力尚可。但拒绝阈值的尾部lift,(650,670]这一箱,正常来说lift是要>1的,但实际<1,说明阈值尾部的精准度不好,可以推测(640,650]这部分拒绝的用户lift应该在1左右,属于风险中等人群,如果这部分人通过对整体坏账影响是比较小的,可以做捞回处理。
刚才介绍了判断规则放松的几个维度,下面讲一下如何对放松的用户做风险判断,这个其实跟风控模型中做拒绝推断类似,可基于以下几点:
1)基于规则对通过用户排序性的推测,刚才例子中的规则B就是这样。如果规则对风险判断有好的排序性,那么可推测出拒绝阈值外尾部的风险表现。
2)基于模型分的拒绝判断,用模型分来衡量被拒人群的风险,这就要求所使用的模型分有比较好的区分能力。例如在老客支用环节,B卡分就是一把比较好的标尺。假设要放松上述例子中的规则A,起初定的阈值为>26拒绝,现在打算放松到>28,那就可以比较(24,26]和(26,28]这个区间在B卡分上表现,如果分布差不多,则说明两个区间用 户的风险程度相近,则放松到>28是合理的。模型分除了做风险判断,也可以对拒绝人群加一道限制,例如用户命中(26,28]这个区间且B卡分在600分以上才予以通过,这样相当于从拒绝样本中再精准的抓出好的用户,可以尽量降低捞回对整体坏账的影响。
3)基于专家经验,如果放松用户不能通过排序性和模型分做推测,可结合市场,政策 环境的变化来预估风险,当然这是一种不得已的手段。
PART 3.捞回在决策流中的应用
1.串行式决策流中的应用
串行式决策流存在规则触发的先后顺序,如果是对上游(先触发)的策略做放松,由于放松的那些用户没触发过下游的规则,那么很难评估放松后对风控通过率的影响。可能你前面的规则放松了,但放松的人都被后面的规则拒掉,通过率没变化,这样捞回就失去了意义。所以针对串行式,优先考虑对下游规则做放松。
另外如果对多条策略做了放松处理,在做决策流部署时可以给捞回的订单打上捞回标记,若订单最终结果是通过,则捞回成功,捞回订单每命中一个放松的规则,则打上一个标记。标记的数量越多,用户的资质越差。举个例子,对A->B->C->D->E五条规则做了放松,且这些规则之间有先后跑的顺序,如果一个用户只打上了A规则的捞回标记,则说明它在BCDE规则上是本来就能通过的,这种人资质就好一点,如果全部命中标记,则说明这5个规则放松之前都认为他是个坏用户。根据标记数量的多少可最终决定被捞订单是否通过,例如放松了5条规则,则标记数<=2予以通过,这种打标记的方法一方面可以输出被捞订单的捞回原因,也可以从中挑选出更好的用户。
2.并行式决策流中的应用
相比于串行,并行式决策流的好处是不管用户是通过还是拒绝,所有的规则都会触发一遍,这样就很容易评估规则放松对通过率的影响。不过并行式的问题是规则之间存在交叉命中的情况,所以在寻找可放松的规则时,需要用不交叉拒绝率来反映规则对于风控决策的权重。(不交叉拒绝率 = 只命中这个规则的用户数/申请用户数)。当一个规则不交叉拒绝率很高,说明很多人都只被它给拒了,对它进行放松就能直接提升整体的通过率,达到立竿见影的捞回效果。
并且在做并行捞回时,可以优先对只命中一两个软规则的用户进行捞回,这些人的资质相对好一点。当放松多条策略时,也要给捞回的订单打上捞回标记。同样可根据标记的数量决定最终是否通过。
PART 4.拒绝捞回的监控
捞回方案上线后,监控是必不可少的环节,毕竟捞回的用户相对风险高一点,需要更加关注捞回的资产质量。
1.前端监控
上线前期还没贷后表现,这时候主要监控捞回订单占比和整体通过率的变化。
主要需要监控的指标:
风控通过率 = 通过订单数 / 申请订单数
捞回订单占比= 有捞回标记的通过订单数/ 总的通过订单数
捞回放款本金占比= 有捞回标记的通过订单放款本金 / 总的放款本金
捞回订单的平均放款金额 = 有捞回标记的通过订单放款本金 / 有捞回标记的通过订单数
捞回订单的占比不宜过高,一般要控制在0-15%之间,假如某天占比突然升高,需要立马排查原因,毕竟捞回用户的资质相对较差。
2.后端监控
当有贷后表现出来后,需要对比下捞回VS大盘的逾期表现,来验证捞回策略的合理性,便于对捞回策略做出调整。
主要监控的指标:
PD指标(人维度) = 当前期数逾期N 的用户数 / 当前期数出账N 的用户数
坏账率 = 逾期N天以上的本金 / 放款本金
如果捞回用户的贷后表现良好,说明捞回的风险可控,可考虑做进一步的风险下探;
如果贷后表现较差,则需要复盘下原因,研究下逾期个案,对捞回策略做优化。
本次专题文章内容将继续跟大家讲解拒绝捞回中的总结跟思考,包括拒绝捞回的总结与实操环节的内容。
PART 5.拒绝捞回的总结和思考
PART 6. 实操环节--拒绝推断(外推法)
其中part6部分,我们会用到外推法进行实操演练,什么是外推法?
外推法的思路简单讲就是拒绝样本的风险是比通过样本高的,我们可以先用通过样本建一个模型,对拒绝样本打分,对其进行分组,然后人为指定一个风险倍数来推断拒绝样本的badrate。具体的实现流程:
1)对通过样本建模,并对通过样本和拒绝样本打分。
2)对通过样本根据模型分进行分组(一般等频),统计每组的badrate,并将拒绝样本按同样的逻辑进行分组。
3)指定一个风险倍数(2-4),将通过样本的badrate乘以风险倍数,就是拒绝样本推断的badrate。
4)根据推断的badrate计算拒绝样本中每组的好用户数和坏用户数,并随机赋予bad和good状态。最后检验整体拒绝样本的badrate是否为通过样本的2-4倍。
5)将拒绝样本和通过样本组合起来建模
更多精彩内容,敬请关注下篇!
~原创文章
...
end
,














