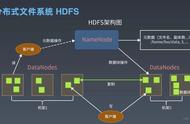
一.HDFS读流程(文件下载)

为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。
如果在读取程序的同一个机架上有一个副本,那么就读取该副本。
如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读取本地数据中心的副本。
语义:下载一个文件
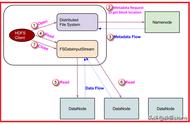
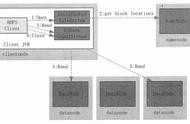
客户端(Client)通过Distributed FileSystem向NameNode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
NameNode会按距离策略排序返回存放相关块的DataNode地址,Client挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
datanode开始传输数据给客户端(从磁盘里面读取数据输入流,以packet为单位来做校验)。
客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
语义:下载一个文件其实是获取文件的所有的block元数据,那么子集获取某些block应该成立
HDFS支持Client给出文件的offset自定义连接哪些block的DataNode,自定义获取数据。这个是支持计算层的分治,并行计算的核心。
二.HDFS写流程(文件上传)

Client和NameNode连接创建文件元数据
NameNode判定元数据是否有效
NameNode触发副本放置策略,返回一个有序的DataNode列表
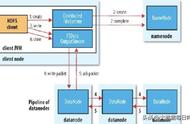
Client与DataNode建立Pipeline连接
Client将块切分成packet(64KB),并使用chunk(512B) chunksum(4B)填充
Client将packet放入发送队列dataqueue中,并向第一个DataNode发送
第一个DataNode收到packet后本地保存并发送给第二个DataNode
第二个DataNode收到packet后本地保存并发送给第三个DataNode
这一个过程中,上游节点同时发送下一个packet
生活中类似于工厂的流水线,结论:流式其实也是变种的并行计算
HDFS使用这种传输方式,副本数对于Client是透明的
当block传输完成,DataNode们各自向NameNode汇报,同时Client继续传输下一个block
所以,Client的传输和block的汇报也是并行的