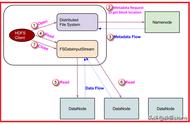
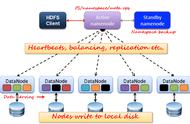
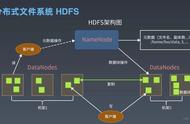
HDFS(Hadoop Distributed File System)是GFS的开源实现。
HDFS的优缺点1、优点
因为有多个副本,可以保证数据可靠,容错性高
计算向数据移动,适用于批处理
适合大数据处理,GB、TB、PB级数据,百万以上的文件,十万以上的节点
可以构建在廉价机器上,通过多副本提高可靠性
2、缺点
不支持低延迟的数据访问,无法再毫秒之内返回结果
小文件对于HDFS是致命的,会占用大量的NameNode的存储空间
并发写入和文件随机修改困难,因为它一个文件在同一时刻只能有一个写入者,而且只支持append
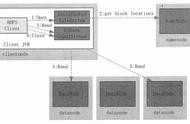
HDFS的写流程
写流程如下:
1、客户端访问NameNode,NameNode检查路径和权限,如果路径中有与要上传的文件重名的文件就不能上传了,不能覆盖,如果没有才创建,创建名为file.copying的临时文件;
2、NameNode触发副本放置策略,如果客户端在集群内的某一台机器,那么副本第一块放置在该服务器上,然后再另外挑两台服务器;如果在集群外,namenode会根据策略先找一个机架选出一个datanode,然后再从另外的机架选出另外两个datanode,然后namenode会将选出的三个datanode按距离组建一个顺序,然后将顺序返回给客户端;
3、客户端会根据返回的三个节点和第一个节点建立一个socket连接(只会和第一个节点建立),第一个节点又会和第二个节点建立socket连接,由第二个节点又会和第三个节点建立一个socket连接,这种连接的方式叫Pipeline;
4、客户端会将block切分成package(默认是64kB),以流式在pipeline中传输
好处:
(1)速度快:时间线重叠(其实流式也是一种变异的并行);
(2)客户端简单:副本的概念是透明的;
5、由DataNode完成接收block块后,block的metadata(MD5校验用)通过一个心跳将信息汇报给NameNode;
6、如果再pipeline传输中,任意节点失败,上游节点直接连接失败节点的下游节点继续传输,最终在第5步汇报后,NameNode会发现副本数不足,一定会触发DataNode复制更多副本,客户端Client副本透明;
7、client一直重复以上操作,逐一将block块上传,同时DataNode汇报block的位置信息,时间线重叠;
8、最终,如果NameNode收到了DataNode汇报的所有块的信息,将文件的.copying去掉,文件可用。
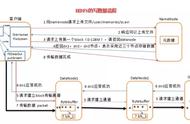
HDFS的读流程
读流程如下:
我们先说一个语义:下载回这个文件。换句话说就是取回这个文件的所有的块,那么当有能力取回文件的所有块的时候,那么它的子集操作就是取回其中某些块或者某个块也能实现。所以我们先来看取回文件的所有块的流程是怎么实现的:
1、客户端和NameNode建立连接,获取文件block的位置信息(fileBlockLocations)
2、客户端根据自己想要获取的数据位置挑选需要连接的DataNode(如果全文下载,从0开始;如果是从某一位置开始,客户端需要给出)
需要用inputstream.seek(long)//从什么位置开始读取,和哪个DataNode开始连接获取block;
3、距离的概念:只有文件系统在读流程中附加距离优先的概念,计算层才能够被动实现计算向数据移动,距离有以下三种:
(1)本地,最近的距离;
(2)同机架,次之的距离;
(3)other(数据中心),最远的距离;
4、客户端下载完成block后会验证DataNode中的MD5,保证块数据的完整性。
看到了这里,你会发现 HDFS 文件系统的读写流程并不复杂,很容易被小伙伴们忽略,所以赶紧mark起来吧!
我是大数据每日哔哔,欢迎关注我,一起聊大数据!