总流程
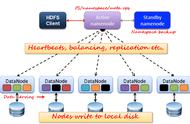
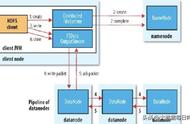
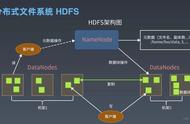
数据读取请求是由HDFS、NameNode、DataNode共同来完成服务的。下图描述了Hadoop中的文件读取操作。

- 客户端通过调用FileSystem对象的open()方法发起读取请求,它的分布式实现类型是DistributedFileSystem,其负责终端用户代码与Hadoop分布式文件系统交互。
- 这个对象使用RPC连接到Namenode,并获取元数据信息,例如文件的块的位置。
- 为了响应这个元数据请求,将返回具有该块副本的DataNodes的地址。
- 一旦接收到DataNode的地址,就会返回一个FSDataInputStream类型的对象给客户端。FSDataInputStream包含DFSInputStream,它负责处理与DataNode和NameNode的交互。在上图中的步骤4中,客户端调用read()方法,使DFSInputStream与第一个DataNode建立连接,并与文件的第一个数据块建立连接。
- 数据以流的形式被读取,客户端反复调用read()方法。这个read()操作的过程一直持续到把块数据读取完。
- 一旦一个块数据读取完毕,DFSInputStream就会关闭连接,并继续寻找下一个区块的下一个DataNode。
- 一旦客户端完成了读取,它就会调用一个close()方法。