QuestDB:探索数据的深度,加速决策的速度- 精选真开源,释放新价值。

时序数据库(Time Series Database,简称TSDB)是一种专门设计和优化的数据库系统,用于高效地存储、管理和查询带有时间戳的数据序列,即时间序列数据。这类数据库的核心特点是处理那些随时间变化的数据,如传感器测量值、服务器性能指标、股票价格、天气数据等,其中每个数据点都关联了一个精确的时间戳。
QuestDB 是一个开源的高性能 SQL 时序数据库,专为金融服务、物联网、机器学习、DevOps 和可观测性等应用场景设计。自2014年开源以来,它一直是一个面向列的时序数据库,旨在优化时间序列和事件数据的处理。
QuestDB 采用 Java 和 C 进行开发,具有较少的外部依赖,目前以单机模式运行,主要基于本地磁盘存储。它支持 InfluxDB 行协议、PostgreSQL 协议,以及通过 REST API 进行查询、批量导入和导出操作。
QuestDB 的 SQL 语言扩展了时间序列功能,使得实时分析变得简单直观。
作为一个时间序列数据库,QuestDB 特别适合处理金融市场数据、应用程序指标、传感器数据等,适用于实时分析、仪表盘展示和基础设施监控等多种用途。它遵循 ANSI SQL 标准,并提供原生的时间序列扩展,简化了多源数据的相关性分析。
QuestDB 的核心优势在于:
- 列存储模型:优化查询效率。
- 并行化向量执行:加快计算速度。
- SIMD 指令集:进一步提升性能。
- 低延迟技术:确保快速响应。 这些特性使得 QuestDB 成为一个在性能和易用性方面都表现出色的数据库解决方案。

QuestDB 采用列存(column-based)存储模型,表里的数据按列存储到不同的文件,每次新的写入数据追加到文件末尾,保持跟写入顺序一致。
追加模型QuestDB 采用列存模型,每个列存储到不同的文件,文件通过 mmap 方式映射到内存,每次写入直接在映射内存大末尾追加数据,非常高效,对于定长类型列,通过行号就能固定定位到数据位置;针对变长类型列,每个列除了对应一个数据文件,还要对应一个索引文件,索引文件的记录为定长,指向各个记录在数据文件的位置。
一致性和持久性QuestDB 能保证每次写入的表级别的原子性,每张表会单独维护 last_committed_record_count(txn_count), 读取时 QuestDB 确保不会读到行号超过 txn_count 的记录,确保与正在写入事务的隔离性,当新记录的各个列都更新成功时,QuestDB commit 事务更新 last_committed_record_coun提交事务。数据的持久性级别可以在 commit 时指定不同的参数,是每次提交持久化还是周期性做持久化。
主要功能尝试 QuestDB你可以在线体验:https://demo.questdb.io,其中包括最新的 QuestDB 版本 和几个样本数据集:
- Trips: 近 10 年的纽约市出租车行程轨迹数据集,含 1.6 亿行的数据。
- Trades: 每月30M 的实时加密货币市场数据。
- Pos: 含有 25 万艘船的时序地理数据集。
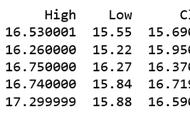
查询 | 运行时间 |
0.15 secs | |
0.5 secs | |
0.02 secs | |
0.01 secs | |
0.00025 secs |

QuestDB采用面向列的存储方式,这种模型在处理分析型查询时,能够提供更高的效率和更低的I/O消耗。
实时分析通过时间序列扩展的SQL,QuestDB能够协助进行实时数据分析,为需要快速响应的业务场景提供支持。
多协议支持支持InfluxDB行协议、PostgreSQL协议和REST API,使得QuestDB可以无缝集成到现有的数据生态系统中。
高性能摄取QuestDB为高吞吐量数据摄取进行了优化,能够快速处理大量数据流入,满足实时监控和分析的需求。
易于扩展QuestDB设计为单机运行,但通过其REST API和支持的协议,可以轻松扩展以适应更大的数据量和查询需求。同时还兼容 PostgreSQL 访问协议,以及 InfluxDB 写入的访问协议。QuestDB 还自带 Web Console,方便数据库的基本访问。

截至发稿概况如下:
- 软件地址:https://github.com/questdb/questdb
- 软件协议:Apache 2.0
- 编程语言:
语言 | 占比 |
Java | 91.4% |
C | 5.7% |
C | 1.9% |
Assembly | 0.9% |
CMake | 0.1% |
- 收藏数量:13.5K
QuestDB以其高性能和实时分析能力,为用户提供了一个强大的时间序列数据库解决方案。它的设计哲学在于简化数据的存储和查询,同时保持高效的性能和易用性。
在处理大规模时间序列数据时,如何平衡存储效率和查询性能?QuestDB通过其列存储模型和向量化的执行引擎,提供了一个高效的解决方案。然而,对于非结构化数据的处理,QuestDB可能需要进一步的优化。社区可以通过开发插件或集成其他工具来扩展QuestDB在这方面的能力。
你在实时数据分析和处理时间序列数据时遇到了哪些挑战?你认为QuestDB在哪些方面可以进一步优化以更好地满足你的业务需求?热烈欢迎各位在评论区分享交流心得与见解!!!声明:本文为辣码甄源原创,转载请标注"辣码甄源原创首发"并附带原文链接。