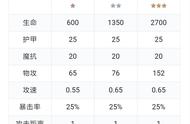
一、计算机系统概论
1. 冯诺依曼计算机组成
主机(cpu 内存),外设(输入设备 输出设备 外存),总线(地址总线 数据总线 控制总线)
2. 计算机层次结构
应用程序-高级语言-汇编语言-操作系统-指令集架构层-微代码层-硬件逻辑层
3. 计算机性能指标
非时间指标
- 【字长】机器一次能处理的二进制位数 ,常见的有32位或64位
- 【总线宽度】数据总线一次能并行处理的最大信息位数,一般指运算器与存储器之间的数据总线的位数
- 【主存容量】主存的大小
- 【存储带宽】单位时间内与主存交换的二进制位数 B/s
时间指标
- 【主频f】时钟震荡的频率 Hz;【时钟周期T】时钟震荡一次的时间 t
- 【外频】cpu与主板之间同步的时钟频率,系统总线的工作频率;【倍频】主频与外频的倍数 =主频/外频
- 【CPI】clock cycles per instructIOn,执行一条指令需要的周期数(平均)
- 【MIPS】million instructions per second,每秒执行的指令总条数 MIPS= f / CPI (忽略单位)
二、数据表示
1. 基本概念
- 真值: 0101,-0100
- 机器数: [x]原=0101
2. 几种机器数
- 原码:x = -0101,[x]原 = 1101
- 反码:x = -0101,[x]反 = 1010
- 补码:x = -0101,[x]补 = 1011
- 移码:x = -0101,[x]移 = 2^n x = 0011
PS:这里说说对补码与移码自己的理解。补码是为了化减法为加法方便计算机设计运算,移码是为了方便比较大小,用在浮点数的阶码中。
补码——任何一个有模的系统中,减法都可以通过加其补码来表示。最简单的例子就是以12为模的钟表,比如现在是3点,那么-5个小时就等于 7个小时,都是10点。这里7就是5的补码。
移码——数据对应关系一次挪动一下位置,使得看起来小的数真值也小。比如原本0000表示0,现在表示-128,然后0001表示-127,一直到1111表示 127,这样就方便比较了。
3. 定点数与浮点数
定点数:小数点固定 x.xxxxxx,表示范围受限,忘掉它吧
浮点数:数的范围和精度分别表示。
一般格式 :EEEE......EMMM.......M,E部分是阶码(数的范围i),M部分是尾数(数的精度)。缺点:阶码和尾数位数不固定,太灵活了
IEEE754格式:跟我背下来----
32位的是(单精度):1位符号位S 8位偏指数E 23位有效尾数M,偏移值为127。
64位的是(双精度):1位符号位S 11位偏指数E 52位有效尾数M,偏移值为1023。
真值就是(32位为例) N = (-1)^S * 2^(E-127) * 1.M
浮点数的特殊情况:
E=0,M=0:机器零
E=255,M=0:无穷大,对应于x/0
E=255,M!=0:非数值NaN,对应0/0
ps:附上一份IEEE754文档:https://files.cnblogs.com/files/flashsun/7542008-2008.pdf
4. 数据校验
基本原理:增加冗余码
码距:合法编码之间不同二进制位数的最小值
码距与检错、纠错能力:
- 码距 d>=e 1:检查e个错误
- 码距 d>=2t 1:纠正t个错误
- 码距 d>=e t 1:同时检查e个错误,并纠正t个错误。(e>=t)
PS:这里说下我的理解,增加码距就是增加非法编码的数量,看到非法编码就算检查出错误了,而非法编码距离哪个合法编码比较进就认为正确的应该是什么(简单理解,可参考下面的图),也就是可以纠正错误。这里看到过一个好的几何理解图,仔细品味下:

举个例子:比如一共有8位,码距为1则检查不出任何错误,因为所有编码都是合法编码。如果码距为2,那合法编码应该像 00000000,00000011,00001100,00001111这样,那如果出现00000001这样的非法编码就出错了,可检查一位错,但如果两位同时错了,则有可能又跳到另一个合法编码上了,就检查不出2位错。
那如果码距是3,那合法编码应该像 00000000,00000111,00111000,00111111 这样,那如果出现一位错 00000001,或者两位错00000011,都是非法编码,都能检查出错误,并且此时可以纠正00000001为00000000,纠正00000011为00000111。但是三位同时错就检查不出了。
常见校验策略:奇偶校验,CRC校验,海明校验
ps:海明编码最强视频演示教程:https://www.youtube.com/watch?v=373FUw-2U2k
三、运算方法与运算器
1. 定点数运算及溢出
定点数加减法:减法化加法,用补码直接相加,忽略进位
溢出:运算结果超出了某种数据类型的表示范围
溢出检测方法:统一思想概括为正正得负或负负得正则溢出,正负或负正不可能溢出
方法1:V = XYS XYS(XY为两个加数的符号位,S为结果的符号位,_表示非),那么V = 1则为溢出
方法2:V = C0 ⊕ C1(C0是最高数据位产生的进位,C1是符号位产生的进位),那么V = 1则为溢出
方法3:V = Xf1 ⊕ Xf2(数据采用变型补码 Xf1Xf2 X0X1X2X3... )
PS:以上方法都是利用正正得负负负得正则溢出为出发点的电路设计
2. 补码一位乘法——Booth算法
[x·y]补 = [x]补·( -y0+∑ yi2-i )
= [x]补·[ - y0 y12-1 y22-2 … yn2-n]
= [x]补·[ - y0 (y1 - y12-1) (y22-1 - y22-2) … (yn2-(n-1) - yn2-n)]
= [x]补·[(y1 - y0) (y2 - y1) 2-1 … (yn - yn-1) 2-(n-1) (0 - yn)2-n]
总结起来设计数字电路的规则就是:
- 为00或者为11的时候,直接右移一位
- 为01的时候,加x的补,然后右移一位
- 为10的时候,加-x的补,然后右移一位
PS:其实第一行和最后一行都能设计数字电路,为什么要从第一个式子推到最后一个式子呢?原因有两点:
1)二进制中如果有0,可以不进行运算
2)如果有连续的1可以减少计算次数,比如 a * 001111100 = a * (010000000 - 0000000100)
所以每次判断 yn 1 - yn就可以减少计算次数了
参考:https://www.cnblogs.com/xisheng/p/9260861.html
3. 定点数除法 --- 略,没找到好的资料
4. 浮点数加减法
(1)求阶差,阶码小的对齐大的
(2)尾数加减
(3)结果规格化
四、存储系统
1. 存储系统层次结构
主存速度缓慢的原因:主存增速与CPU不同步,执行指令期间多次访问主存
主存容量不足的原因:
- 存在制约主存容量的技术因素:如由CPU、主板等相关技术指标规定了主存容量
- 应用对主存容量需求不断扩大:window98 -- 8M,windows 8 -- 1G
-----> 存储体系结构化层次: CPU -- cache1 -- Cache2(解决速度) -- 主存 -- 辅存(解决容量)
存储体系结构化层次理论基础:
- 时间局部性:程序体现为循环结构
- 空间局部性:程序体现为顺序结构
2. 主存中的数据组织
存储字长:主存的一个存储单元所包含的二进制位数,目前大多数计算机主存按字节编址,主要由32为和64位
数据存储与边界的关系:
- 按边界对齐的数据存储,未按边界对齐的数据存储
- 边界对齐与存储地址的关系:(32位为例)
- 双字长边界对齐:起始地址最末三位为000(8字节整数倍)
- 单字长边界对齐:起始地址最末二位为00(4字节整数倍)
- 半字长边界对齐:起始地址最末一位为0(2字节整数倍)
大端与小端存储方式:
- 大端:最高字节地址是数据地址(0123存成0123)
- 小端:最低字节地址是数据地址(0123存成3210)
3. 存储器分类
- SRAM存储器:存取速度快,但集成度低,功耗大,做缓存
- DRAM存储器:存取速度慢,但集成度高,功耗低,做主存
DRAM刷新方式:集中刷新、分散刷新、异步刷新
4. 主存容量的扩展
- 位扩展法:8K * 8位 --> 8K * 32位
- 字扩展法:8K * 8位 --> 32K * 8位
- 字位同时扩展法:8K * 8位 --> 32K * 32位
5. Cache的基本原理
cache的工作过程
- 数据:cpu与cache交换字,cache与内存交换块
- 读:命中,不命中
- 写:写穿策略,写回策略
写策略
- 写穿策略(write through):同时写缓存和内存,好像穿过缓存一样。若不命中,先写到主存中,并选择性地同时分配到缓存中(写分配/非写分配)
- 写回策略(write back):写到缓存后不管了,只有当缓存的内容替换回主存时再管,需有脏位。好像隔段时间后再写回到主存中一样
地址映射机制
- 相联存储器:地址本身包含着位置啊可比较的信息啊等内容信息,可根据区分地址内容进行寻址
- 主存地址 = 块地址 块内偏移地址 = (Tag Index) 块内偏移地址
- cache结构
- 好多行,每行与主存块大小相等
- 每行 = tag data valid dirty
- 三种映射方式
- 全相联:cache行号 = random(内存块号)
- 直接相联:cache行号 = 内存块号 % cache行数
- 组相联:两者结合。8行1路组相联就是全相联,8行8路组相联就是直接相联
替换算法
- 先进先出法-FIFO
- 最近最不经常使用法-LFU
- 近期最少使用法-LRU
- 随机替换法
6. 虚拟存储器
解决问题:主存容量不足。希望向程序员提供更大(比主存大)的编程空间
分类:页式,段式,段页式
页式实现方式:MMU(Memory Management Unit) 页表 TLB(Transaction Lookaside Buffer:地址转换后备缓冲器)
页式转换过程:虚拟地址 = 虚拟页号 页内偏移 ==> 物理页号 页内偏移
7. RAID
概念:独立磁盘构成的具有冗余能力的阵列(Redundant Arrays Independent Disks)
核心技术:使用异或运算恢复数据 (x⊕y = z --> x = y⊕z)
分类:
- RAID0:条带均匀分布
- RAID1:以镜像为冗余方式
- RAID3/4:有校验盘
- RAID5:校验信息分布式
- RAID10/01:10是先镜像再条带化,01是先条带化再镜像
- RAID50:先RAID5,再条带化
五、指令系统
1. 指令系统基本概念
指令集:一台机器所有指令的集合。系列机(同一公司不同时期生产);兼容机(不同公司生产)
指令字长:指令中包含的二进制位数,有等长指令、变长指令。
指令分类
- 根据层次结构:高级、汇编、机器、微指令
- 根据地址码字段个数:零、一、二、三地址指令
- 根据操作数物理位置
- 存储器-存储器(SS)
- 寄存器-寄存器(RR)
- 寄存器-存储器(RS)
- 根据指令功能:传送、算术运算、位运算、控制转移
指令格式:操作码 数据源 寻址方式
2. 寻址方式
指令寻址方式:顺序寻址,跳跃寻址
操作数寻址方式:
- 立即数寻址:地址码字段是操作数本身 MOV AX, 200H
- 寄存器寻址:地址码字段是寄存器地址 MOV AX, BX
- 直接寻址:地址码字段是内存地址 MOV AX, [200H]
- 间接寻址:地址码字段是内存地址的地址 MOV AX, I[200H]
- 寄存器间接寻址:地址码字段是存内存地址的寄存器地址 MOV AX, [BX]
- 相对寻址:操作数地址 当前PC的值
- 基址寻址:操作数地址 基址寄存器的值(一段程序中不变) MOV AX, 32[B]
- 变址寻址:操作数地址 变址寄存器的值(随程序不断变化) MOV AX, 32[SI]
3. MIPS
三种指令格式
- R型指令
- I型指令
- J型指令
六、中央处理器
1. CPU的组成与功能

2. 数据通路
概念:执行部件间传送信息的路径,分共享通路(总线)和专用通路
抽象模型:时钟驱动下,A --> 组合逻辑 --> B
D触发器定时模型:
- 时钟触发前要稳定一段时间:建立时间(Setup Time)
- 时钟触发后要稳定一段时间:保持时间(Hold Time)
- 时钟触发到输出稳定的时间:触发器延迟(Clk_to_Q)
- 与时钟周期的关系:
- 时钟周期 > Clk_to_Q 关键路径时延 Setup Time
- Clk_to_Q 最短路径时延 > Hold Time
3. 指令周期
指令执行的一般流程

基本概念
- 时钟周期 = 节拍脉冲 = 震荡周期
- 机器周期 = CPU周期 = 从主存读取一条指令的最短时间
- 指令周期 = 从主存读指令并执行指令的时间