编辑导语:在我们的日常工作中,很多时候都会用到数据分析的方式,其中建模分析的方法也是数据分析的一种类型,对于各种数值能够清晰明了的呈现;本文作者分享了关于数据分析中的建模分析的基本流程,我们一起来了解一下。

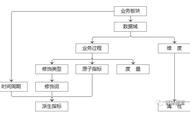
日常的数据分析工作中,除了基本的拆解法、对比法做分析外,也经常需要用到模型的方法来做预测或者分类,这里会介绍建模分析的基本流程及常见处理方法。
01 描述性分析在拿到数据后,不能着急立刻开始清洗数据或者模型训练,而是先了解数据(除建模分析外,其他的数据开发也要做这一步),这样才能避免后期的踩坑,否则十有八九是要复工的。
那“了解数据”这一环节,具体要了解哪些东西呢?
- 了解各个特征的业务含义和计算逻辑
- 各个特征的分布是否符合预期
- 特征之间的相关性如何,是否符合基本逻辑
- 特征和目标值的相关性如何,是否符合基本逻辑
在相关性分析这里,数值型变量之间可通过计算相关系数或者画图呈现;数值型变量和分类变量可通过箱线图呈现关系。
02 缺失值处理在初步了解数据后,需要做一些数据预处理的行为。
第一步就是对缺失值处理,一般根据样本量多少以及缺失比例,来判断是“宁缺毋滥”的删除,还是缺失值填充。
具体处理的思路可以是这样的:
- 统计计算样本量n,各个特征数据缺失率y,各样本数据特征缺失率x;
- 特征缺失率x比较高的样本一般都建议删除;因为多个特征都缺失,填补也比较困难,即使填补信息偏差也会比较大。
- 如果某特征缺失率y比较大,则删除此特征;如果特征缺失率低且样本量比较大的话,可删除特征缺失的样本;如果样本量少不可删除,则对缺失值做填充。
缺失值填充的方法有:
- 根据特征的众数、中位数或者平均值来填充;也可以对样本做分类,根据所在类的平均值众数等填充;
- 通过回归法来做样本填充,缺失值作为因变量,其他特征做自变量去预测;
- 还可通过比较复杂的方法,如多重插补法。
处理完缺失值后,需要做异常数据处理。
之前介绍过一篇异常数据处理的方法,数据分析-异常数据识别;这篇介绍了多种适应不同场景下的异常数据识别方法。
04 数据标准化处理对于很多模型,如线性回归、逻辑回归、Kmeans聚类等,需要计算不同特征的系数,或者计算样本距离。
这种情况下,如果不同特征的数值量级差的特别大,会严重影响系数和距离的计算,甚至这种计算都会失去意义;所以在建模前必须要做的就是要去量纲,做标准化处理。
当然有些模型是不需要做数据标准化处理的,如决策树、随机森林、朴素贝叶斯等。
当前最常用的数据标准化处理方法有:
1)最小—最大规范化
(x-min)/(max-min),将其规范到[0,1]之间
2)z值规范化
(x-均值)/标准差,将其规范为均值为0,标准差为1;
如果这种情况,受离群点影响比较大的话,可以用中位数代替均值,用绝对标准差代替标准差。
还需要注意的是,如果样本分布非常有偏的话,可以先做box-cox变换,将其往正态分布变换后再标准化。
05 特征选择在做完基本的数据清洗以及特征变换后,需要做的是特征选择,一般做特征选择的原因是:
- 某些特征存在多重共线性,这种情况对线性回归和逻辑回归影响比较大;
- 特征太多,有些特征增加了模型复杂性却与模型无关,不能全部入模,需要筛选出价值更高的特征。
1. 多重共线性
是什么:模型的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
影响:
1)影响模型的稳定性,而且影响模型的解释。
举个例子,假设消费支出=0.3*收入,这样可能的模型输出的是:
消费支出 收入1.3*收入1.6*收入-消费支出
同样的数值输出,不同的公式计算,会非常模型解释和稳定性的。
2)线性回归模型,会导致最小二乘估计无法计算系数,即使可计算系数方差也很大,即1)中提到的不稳定。
怎么识别:
- 计算特征之间的相关系数,对于相关性特别高的特征,根据业务需要保留有代表性的特征;
- 方差膨胀因子(VIF)。
计算每个特征被其他特征拟合的情况,如特征j,被其他特征线性拟合的决定系数为R2;通常拟合越好,决定系数就越大且最大可达到1。
所以,当方差膨胀因子过大,说明此特征存在多重共线性。一般大于10会认为有比较强的多重共线性问题。
怎么解决:
- 删除共线性强的特征;
- 线性回归模型的话,可采用岭回归的估算方式解决。
2. 特征太多
不同的模型和应用场景下特征筛选方式不同:
- 对于二分类问题来说,筛选逻辑是:筛选出对二分类结果区分度比较高的特征;可以通过计算IV(information value)值的大小来筛选,一般IV值越大,此特征对二分类结果更有区分度。
- 对于回归预测问题,主要针对多元线性回归。筛选特征的方法有:特征子集选择法、正则化法以及降维法。
1)特征子集选择法
特征子集选择法有向前逐步选择法和向后逐步选择法:
a)向前逐步选择
具体方法就是从0个特征开始,一个一个逐步从剩余特征中添加使得模型拟合误差最小的特征,在添加过程中得到模型拟合最优的特征组合。
b)向后逐步选择
和向前逐步选择类似,只是反过来了,让所有特征入模,再一步一步剔除效果不好的特征,从而达到最优。
2)正则化压缩无意义特征的系数
比较好用的方法是lasso。
一般的线形回归我们只会希望它的误差平方和最小,但是lasso的目标函数在原有目标函数后面加了一项系数惩罚项。这样让目标函数最小,可以实现无意义特征的系数为0,从而实现特征选择。
3)PCA降维
这个是将原有有一定线性关系的特征线形组合成新的相互独立的特征,所以不适合原有特征已经相互独立的情况。
以上就是数据建模的前期准备流程,做完这些内容就可以开始模型训练,对模型结果进行预测分析啦,而这部分则是不同模型会有不同的具体处理方法。
总之,模型训练前的数据分析、数据清洗以及特征选择非常重要,甚至他们是决定建模是否成功的关键因素,所以这部分工作一定要做细做准确。
感谢阅读,以上就是我要分享的内容~
作者:须臾即永恒;公众号:须臾即永恒;
本文由 @须臾即永恒 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议