这里引用下我老师写的新书中对数学模型和数学建模的定义,我觉得算是一个比较不错的版本,这里分享给大家:
数学模型是利用系统化的符号和数学表达式对间题的一种抽象描述。数学建模可看作是把问题定义转换为数学模型的过程。 和问题定义相对应,数学模型包括几个主要组成部分:决策变量、环境变量、目标函数和约束条件。决策变量表示决策者可以控制的因素,即可控输入,是需要通过模型求解来确定的模型中的未知变量。环境变量表示决策者不可控的外界因素,即非可控输入,需要在收集数据阶段确定其具体数值,并在模型中以常量表示。目标函数是指描述问题目标的数学方程,而约束条件则是指描述问题中制约和限制因素的数学表达式(等式或不等式)。(这个主要是规划的一种定义) 数学建模是一项富有创造性的工作。对任何问题,“没有唯一正确的模型”。数学模型是对现实问题的一种抽象描述,必然会忽略一些因素。而这些被忽略的看似无关或不重要的因素,可能会引起重大的变化,例如人们熟知的“蝴蝶效应”。著名的统计学家乔治·博克斯曾说过:“All models are wrong.Some are useful.”(所有的模型都是错误的,但有一些是有用的。)对同一问题,可以从不同角度对其构建出多个不同的模型。 对于复杂问题的建模,很难一步到位,通常需要采取一种逐步演化的方式来进行。从简单的模型开始(忽略一些难以处理的因素),然后通过逐步添加更多相关因素,让模型演化,使其与实际问题更加接近。基于模型分析得出的结论或建议的价值,与模型对实际情况的描述符合程度有很大的关系。通常,模型越接近实际,分析得出的结果的价值也越大。
除此之外,美国最为权威的数学建模参考书Mathematical Modeling 在前言部分对数学建模也有着一个比较通俗易懂的解释:
Mathematical modeling is the link between mathematics and the rest of the world. You ask a question. You think a bit, and then you refine the question, phrasing it in precise mathematical terms. Once the question becomes a mathematics question, you use mathematics to find an answer. Then finally (and this is the part that too many people forget), you have to reverse the process, translating the mathematical solution back into a comprehensible, no-nonsense answer to the original question. Some people are fluent in English, and some people are fluent in calculus. We have plenty of each. We need more people who are fluent in both languages and are willing and able to translate. These are the people who will be influential in solving the problems of the future.
翻译的拙作见下:数学建模是数学与世界其他地方(其他领域)之间建立的联系的方法。您提出一个问题,然后稍作思考,然后细化问题,最后以精确的数学术语表述。一旦问题变成数学问题,您就要使用数学来找到答案。最后,最后(这是很多人忘记的部分),您必须逆转这一过程,将数学解转换回对原始问题的可理解的,有意义的答案。
我们知道,有些人说英语流利,有些人做微积分运算熟练,擅长不同领域的人多种多样。我们需要精通不同领域的人并且愿意将不同领域进行转化,这些人将对解决未来的问题产生影响。
这两本书实际上都清晰地说明了数学建模的特点,一个从方法上,一个从思想上。这里我稍微总结一下:
从思想上:
从思想上来说,数学建模是构建数学与其他学科之间的桥梁。我们所谓的交叉学科,很大概率就是以数学、统计学、物理学作为理论基础,计算机作为计算或可视化利器,对某些学科进行定量分析。比如现在流行的生物信息学、整合生命科学、商业分析,或者Computational XX的相关学科,基本上都和数学建模相关。
从技术上:
从技术的角度上来说,数学建模从来都不是强迫症的乐园。因为,我们通过上文已经得出,数学模型本身是不完美的,因此我们要容忍一定程度上模型对原型的“失真”。并且由于选择的因素的侧重点不同,很有可能两个团队使用了不同数学领域的方法对问题进行分析并建立模型。但是,正是这些丑陋并且存在误差的模型,解决了我们生活中很多方方面面的问题。数学模型的建立、求解和应用是人类的理论向着社会应用的一大跃进。
数学建模的主要过程下面主要来谈谈数学建模的主要过程,或者我可以说是数学建模的整个生命周期是怎么样的。这里我同样使用中外两个不同版本的教科书对这个问题的看法,首先第一本是大家参加数学建模竞赛中可能已经使用过的教材:A First Course in Mathematical Modeling,这本教材中出现的数学建模五步法 ,应该是大家耳熟能详的,这里给大家分享一下:

数学建模五步法
下面是我老师教材中关于数学建模的一般流程 。这个流程与数学建模五步法相比,更加贴近实际项目中的流程,这里我使用AxGlyph绘制下改流程图:

基于模型解决问题的一般流程
这个流程图便是基于模型解决问题的一般流程,数学建模五步法与其相比更加精简,更适合在数学建模竞赛中应用,而该流程在实际生活中更具指导意义。还有一种是我们数学建模竞赛中常常走的写作套路,这里也和大家分享一下:
摘要
1.问题重述(背景介绍、文献综述、问题重述等)
2.问题分析(主要对问题进行一定的分析,可以做一个分析流图)
3.问题假设(其实也就是对问题的边界进行划定,我们需要让问题更具体一些)
4.符号说明(对于文章中主要出现的符号进行一定的解释,方便评委老师理解)
5.模型建立与求解(这一步最为核心,即数学建模和模型的求解部分)
6.灵敏度分析(即分析模型的输出,对参数或环境变化的敏感程度的分析)
7.模型的推广及优缺点(主要对模型的进一步研究分析和优缺点解释)
参考文献
附录
我们可以对基于模型解决问题的一般流程中的步骤进行一定的分析:
首先是定义问题和收集数据环节。我认为这是上述流程中最为困难也最容易让人感到很虚无缥缈的一个部分。首先,由于我们每个人说话的方式和对问题的理解程度不同,可能同一件事务,从不同的人口中或者行为中或者情感中表现出来是不太一样的。其实有一个游戏就是利用了这种特点,这种游戏叫做心有灵犀游戏 ,意思就是说,一个人看到一个词汇,通过扮演这个词汇,让另外一个人理解并且将这个词说出来。一般而言,不经过一定程度的训练,是很难让两者协调地进行这个游戏的。或者我们换一个理解,更简单地说,我们知道存在失真这个名词,我们不同的人对一个事务的理解,都会存在不同程度的失真,然后再通过语言或者其他行为传递处于会形成二次失真。下面我引用一段话 :
如果负责解决问题的人和负责提出问题的人对问题的理解不同,其结果可想而知。从“错误”的问题出发,很难得出“正确”的答案。
有时候,我们对于一个要解决的问题,可能并没有真正理解问题的本质,可能问题本身并不是一个问题,或者这个问题在很多年之前被人已经发现了,这样的情况在科研界是很容易出现的。比如之前吵得沸沸扬扬的关于一种新的特征值解法 ,陶哲轩在这一块也犯了这样的错误。对于我们普通人来说,更可能如此,一些问题只是拍脑袋想出来的,并没有深思熟虑。
很多人曾经指出:“能够准确地提出问题,就相当于这个问题已经解决了一半。”因此,定义问题是解决问题的首要环节。
问题的定义主要有两个部分,分别是确定目标和划定边界。我们的目标应该是可以量化并且可以实现的,目标可能有一个目标,可能有多个目标,也可能是一个目标下有很多子目标。其次,我们需要划定边界,因为一个问题受到的影响因素有很多,我们需要做出取舍,找出主要矛盾,舍弃次要矛盾。这对于我们来说,实际上都是非常容易让我们头大的事情。
但幸运的是,对于广大技术工作者或数学建模竞赛爱好者来说,上述问题基本上都是现成的,都是由相关机构或者相关人员经过深思熟虑后考虑的问题,我们只需要好好思考模型,去解决问题就好了。
收集数据,我认为是另外一个老大难的问题。很多人参与过科研项目或者数学建模竞赛的人都知道,有时候,即是是一个非常简单的问题,或者是一个非常成熟的问题,没有数据,什么都是白搭,巧妇难为无米之炊。因此,我们需要开动脑筋,发挥自己和合作伙伴的优势,争取扩大自己的数据使用权和数据获取渠道能力。同时,收集数据对定义问题也很重要 :
在定义问题的同时,还需要收集相应的数据。收集数据可以验证对问题的定义是否合理。
我们可以通过问题的指导下去收集可能可以解决问题所需要的数据,同时我们也可以根据数据收集的程度,反过来看是否需要修改问题的影响因素或边界条件。
数据的收集通常是一个很繁琐的工作,我们往往希望乞求于有专业的组织或者个人可以给我们分享数据。某些数据我们可以根据网上现存的,如国家统计局的数据,而更多时候,我们只能通过自己收集,需要通过大量的调研、收集和整理。现在很多大企业越来越注重数据的收集、清洗、存储,在未来大数据时代中,数据驱动和“以数据为王”会成为很多企业坚定发展的目标。
有时候因为数据收集上存在一定的差距,因此在很多和建模相关的竞赛中都给与数据,这样可以尽最大可能保证比赛更多地是在比较模型的优劣。因为有时候,收集到一份非常有意义并且是独家的数据,哪怕使用最简单的图表分析和描述性统计,也能做出较为有意义的解释。目前在数学建模竞赛中,全国大学生数学建模竞赛和全国研究生数学建模竞赛是两个相对数据上保证公平的比赛,建议大家多多参与。
好了以上是关于定义问题和收集数据环节的解读,下面我们可以聊聊其他环节。
下面的两个环节可以放在一起来说,即数学建模和模型求解。在数学建模竞赛中,这个对应的环节是模型建立与求解,也是最为核心的步骤。同时,这应该是我们广大看这个问题的人,最为关心的问题,即我应该如何建模,并且模型应该如何进行求解。
在前面我们已经说过 :
数学模型是利用系统化的符号和数学表达式对间题的一种抽象描述。数学建模可看作是把问题定义转换为数学模型的过程。
大家可以回到文章中的最前面去阅读关于数学建模的全部叙述,这里就不再重复,总而言之,这可能是对于很多本科学生甚至高中学生来说,可能第一次接触数学建模,会觉得这是一个“肮脏”的事情。因为种种的假设以及原理不清楚、不明显,导致不觉得这是一个完美的、普世的。尤其是刚刚学完高中物理或者数学的同学,会觉得一切都是完美的、精确的。可能认为解题仅仅是高考那样,写出详细解答过程,得出答案即可。但事实上,我们阅读很多数模相关的论文,其中处处充满了妥协,特定的、理想化的、某一类的、近似的等不完美的词汇出现在模型的建立过程中,对于低年级的学生来说,需要适应这种过程的转变。我们只能尽自己最大的努力,让模型可以更加接近实际,让模型的价值体现出来。
下面谈谈模型的求解部分。对于模型的求解这一部分,我同样引用了一段话 :
数学模型中通常包含一些未知变量,如决策变量,需要通过模型求解来获得其(最优)取值。模型求解就是为了找出一组满足所有约束条件,同时使得目标函数值为最优的决策变量取值。
一般而言,模型的求解主要有以下两种形式 :
1.确定可行解的范围,在该范围中通过某种方法寻找最优解。
2.找到一个可行解,通过某种方法逐步对其进行优化,直到无法优化为止。
从上述的两种求解策略中,我们可以感受到计算的工作量巨大。因此,我们是很难使用草稿纸去进行计算出一个结果。这种使用计算机进行计算的方式,在大学以前,大家很少有机会去尝试。因此一般而言,有一个稍微痛苦的适应过程。在计算模型的工具的选择上,从是否要编程的角度来说,可以分为按钮式操作和编程式操作(现在很多软件同时支持这两种操作,我只考虑大家更加习惯倾向的使用方式)。从是否商业化的角度可以分为商业软件和开源软件,在下面我们可以简单举几个例子:
1.MATLAB(编程操作 商业软件)
2.Python(编程操作 开源软件)
3.R(编程操作 开源软件)
4.SPSS(按钮操作 商业软件)
5.SAS(编程操作 商业软件)
6.Julia(编程操作 开源软件)
7.STATA(按钮操作 商业软件)
8.Eviews(按钮操作 商业软件)
9.Origin(按钮操作 商业软件)
10.Wolfram(编程操作 商业软件)
11.Excel(按钮操作 商业软件)
实际上还有非常多的工具这里无法一一列举。大家可以根据自己的实际需要进行学习,可能是因为自己在学校选修了某一门语言,或者因为某个项目的契机刚好快速学习了某种语言,总之自己喜欢哪个,想上手哪个就用哪个。到了后期,因为自己的专业需求或者因为该领域的老师建议,再做出更加具体的选择。
从上面的介绍可以看出,很多软件的主要还是通过按钮操作,因此对于我们广大文科、经管类学生来说,尝试使用数学模型去解决一些问题的门槛,也没有那么高。对于理工科学生来说,学习一些语言的同时,实际上已经顺手掌握了一门可以用来求解模型的语言。
对于求解的结果,我们可以使用不同的形式进行表达,可以使用干巴巴的数据、可以使用一系列的表格、也可以使用不同的图表进行可视化表示。在今天大数据时代,数据可视化越来重要。由于海量的数据对于决策者来说很容易摸不清头脑。这时候有一张较为清晰的图表,对于决策者来说,更加容易理解当前的结果并做出合理的判断。
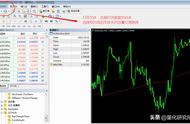
对于市面上存在的林林总总的使用教程,虽然有些书写的不错,但是并不是最好的。最好的教程永远都是help文件或者技术文档。比如MATLAB的help文件几乎介绍了所有你可能用到的功能,并且给予了代码示例 ,从下图我们可以看出,帮助文档非常全,基本上过一遍自己需要了解的内容,就可以上手开始了:

MATLAB帮助文档菜单
比如我想学习多元线性回归并且想绘制回归曲线出来,我们查阅了MATLAB的帮助文档,得到下面的这种求解办法 :
load carsmall
Year = categorical(Model_Year);
tbl = table(MPG,Weight,Year);
mdl = fitlm(tbl,'MPG ~ Year Weight^2');
plot(mdl)

MATLAB绘制出来的曲线
我们可以通过这种办法,一点点地去了解一个语言。其他的语言也是类似,比如你想使用Python下的可视化包Matplotlib 或者Seaborn ,你也可以去相关的官网去了解如何使用。这可能比你买书后,再去一页页翻书,效率要高得多。R语言也是进行类似操作。
用一句话总结,想学什么包,就去什么包的官网或者开源组织上去围观学习一圈,这样应该是学习使用这种包的一种比较有效率的方法。
对于文科学生来说,在做一些简单的统计模型或者计量模型的时候,可能会犹豫到底是使用SPSS/SAS/STATA/Eviews中的哪一种好,毕竟由于大体都是按钮式或者编程不是那么复杂,因此主要还是应用应该更有针对性,人大经济论坛上有一篇分析以上四种工具的比较文 ,我觉得还不错。
还有我们应该稍微注意下商业软件的版权问题,我在这里还是不建议大家使用盗版软件。很多开源软件如Python和R现在已经是非常强有力的模型求解武器。对于在校学生来说,MATLAB在很多学校也有开放正版软件的使用许可,对于参加全国大学生数学建模竞赛的同学,也有申请免费使用的许可。大家可以根据自己学校的特色和倾向性对工具进行选择。
以上稍微介绍了一下如何快速上手相关工具的经验分享,可能有点和这个问题的主题并不完全相关,但是我觉得作为很多同学的疑惑,在这里很有必要说清楚。
最后关于大学生数学建模竞赛,我适当补充一些对于刚刚开始尝试这项比赛的选手的做题的办法,我将其称之为黑箱理论 。因为对于大学生来说,短期内彻底明白一个比较热门的模型是很困难的,尤其是这道题目并不是我们专业相关的。我有一个比较生动的例子:你需要学会使用锤子,但是你暂时还不需要学会造锤子!
关于一些较为基础的模型,大家可以去我的朋友的CSDN下的博客 上进行学习。关于数学建模竞赛相关的问题,大家可以关注我的回答集合 ,希望这个回答可以帮助到大家。其实挺希望未来的学习门槛可以继续降低,最好可以游戏化,比如Python学习上就有类似的工作 。
关于模型解决问题这一流程中最关键的问题叙述完毕!下面我们来谈一谈优化后分析(灵敏度分析)这一步。
这一步说老实话,很多人都搞不清楚,也对这个问题避而不谈,在数学建模竞赛中,大家在这个环节上一般草草了事或者套一套模板,或者直接避而不谈。这里我稍微谈一谈吧。
一般而言,我们所求解的结果是一个非常理想化的结果,即是建立在一个合理的假设后的模型,并且其环境变量是准确的或较优的。在优化后分析这一步,我们假设模型是合理的,而重点分析环境变量的取值,和在环境变量下取值的变动进行讨论和分析。关于环境变量的叙述见下 :
环境变量是我们对未来环境状态的一种估计,因而不可避免地会存在一定的误差。同时,在方案实际执行过程中,环境变量的取值还可能会发生不同程度的变化。而环境变量取值的变化,可能会导致模型的最优解和目标函数的最优值发生变化。如果依据当前模型的最优解做出决策,就存在一定程度风险。为了缓解或是避免环境变化可能造成的风险,在提出决策建议前还需要进行优化后分析。
以上是环境变量的解释,以及环境变量对模型的影响。下面是一个对优化后分析的一种定义 :
优化后分析也被称为敏感性分析,即分析模型最优解和最优值对某一个或多个环境变量发生变化的敏感程度,是一种评估候选方案风险的不确定性分析方法。敏感性分析有两种常见的方法:一是分析在最优解(即最优方案保持不变)的情况下,各个环境变量允许变动的范围,称为可变范围;二是使环境变量在特定范围内(通常是在当前估计值的周围)变动,观察相应的模型输出变化的情况。
一般而言,在数学建模竞赛中,大家在做敏感性分析时,倾向使用图表来描述一个模型输出情况。这样的原因主要有以下几点:第一,大家一般在做敏感性分析时,到了比赛的末尾阶段,可能大家多多少少感到时间上不够用。一般决定做敏感性分析的队伍,基本上都是要决定冲击国家一等奖的队伍,更多的队伍选择放弃这个部分,直接对文章进行收尾工作。所以,对非常有限的条件进行“调参”,在这个基础上,把一系列的输出用图像的形式进行表示,这样不仅节省时间,而且由于图像直观易懂,评委可以马上清楚模型在环境的影响下会如何出现变化。
对于环境的可变范围,也有一定的讲究 :
由于实际环境固有不确定性,导致决策不可避免地会存在一定程度的风险,敏感性分析有助于降低这种风险。一般而言,环境变量可变范围越大,则实际超出该范围的可能性就越小,对应的风险也就越小。反之,可变范围越小,则实际超出该范围的可能性就越大,对应的风险也就越大。
对于模型的解而言,可能最优解经过敏感性分析后发现其环境变量的可变程度较小,因此虽然结果较好,但是十分受到环境的制约,存在较大的风险。而一些输出可能结果不如最优解,但其环境适应能力较好,对于不同的决策者会有不同的选择。因此虽然说在数学建模竞赛中,我们为了赶时间可以不进行这个分析,但是在日常生活中,做相关分析时,可不能忘记了,其存在的风险可能会真正影响到我们的生活。我们熟悉的投资组合模型就是利用了这一思想。
下面我们来谈一谈模型检验。模型的检验相当于是一项工程的验收阶段,由于我们的模型是对现实世界的一种抽象表示,一种高度概括,其合理性是由我们对模型的相关假设是否正确、是否反映现实所确定。由于我们知道,所有的模型都不是完美的,都存在一定的“失真”,因此在模型使用之前,我们需要通过一些手段,对模型进行检验,来确保我们的模型可以真正地应用到现实问题上去。下面是模型检验的定义 :
把模型求解和分析得到的结果与所研究的实际问题进行对比分析,以检验模型的合理性,称为模型检验。如果检验发现模型结果与实际不符,则应该修正假设或是改换其他方法重新构建模型。通常一个模型需要经过多次反复修改,才能得到令人满意的结果。
以上是模型检验的定义,在数学建模竞赛或者很多模型类比赛的流程中,这一步往往很少单独拿出来作为一个流程进行分析。而是模型的建立与求解中,间接地进行模型的检验了。比如我们会将一些历史上的数据代入模型来检验模型的准确性,或者根据生活常识来判断模型的计算合理不合理。对于实在是没有数据的情况下,我们可以做仿真,生成大量的数据,来通过这些数据对模型进行验证分析。
在做出模型检验时,我们一般默认我们的模型是好用的,结果是精确的,然后我们通过不同的案例,不同的输入来验证这个模型是否正确。通常我们对于模型的检验的常用方法有以下三种 :
1.第三方测试,这一点通常是数学建模竞赛或相关赛事没有办法做到的模型检验的方法,
因为我们在比赛完了之后,才有所谓的第三方评委帮我们进行阅卷。我们在进行模型验
证时,最好找一个从来都没有参与过模型构建的人,以他自己的视角重新检验问题的定
义和模型的构建是否合理,或者从不同的角度,再构建一个或多个新模型,并将其结果
与原模型进行对比。模型越多,出现同样错误的概率越小。从以上文字我们可以看出一
件非常有意思的事实,由于对于我们每个人来说,数学建模竞赛是无法做到第三方测试
的,但是对于组委会来说,则是一个没有标的,即无监督的大型第三方测试。意思就是
说,不同的参赛作品互为第三方测试,最终组委会在所有的模型中选择两个最好的模型
授予“高教社杯”和“MATLAB创新奖。”
2.回溯检验,使用历史数据重现过去来检验所构建的模型在历史环境中的应用效果。虽
然模型的应用场景是未来,但是未来没有来临,我们无法进行对比分析。但在很多的应
用中,已经积累了大量的历史数据,可以用来模型的检验。虽然过去不一定代表未来,
但是如果模型在已经知道明确结果的过去都无法给出一个令人满意的结果,就很难说服
决策者相信这个模型能够在一切都还未知的未来,会给我们带来预期的使用效果。在数
学建模竞赛中,回溯检验是一个我们较为常用的检验方法,我们通常可以带入一些已经
有的数据对模型进行检验。比如2017年的数学建模国赛A题,第一问和第二三问就是一个
内容,两个方向的过程。对于绝大多数数据驱动类的问题,都可以采用回溯检验对模型
进行验证。
3.计算机仿真,如果我们没有足够的历史数据用来进行回溯检验,可以尝试利用计算机
来对模型的运行环境进行模拟仿真,生成大量的测试数据,并利用这些数据对模型进行
验证分析。如我们较为熟悉的蒙特卡洛模拟就是一个常用的仿真方法。一般而言,仿真
常出现在数据量不足或不给数据的比赛,如美国大学生数学/交叉学科建模竞赛,通常
就要通过对模型进行仿真来验证模型的合理性,如2019年D题有关卢浮宫逃生路线设计,
就需要使用这种方法来对模型进行验证。
以上是关于模型检验的介绍,下面是有关提出建议、做出决策和方案实施与观察的介绍。提出建议、做出决策和方案实施是一次基于模型解决问题的最后一步。提出建议主要是根据优化后分析和模型检验后的理想模型和备选模型给出建议,以及这些模型背后的某种决策方案进行建议。之后则需要解决问题的人对这些模型进行选择,即“选择应该使用哪一把螺丝刀进行工作,”,对于不同性格的决策者,可能会对某些模型、对某些结果存在一定的偏好,我们应该对这种非理性的因素给予尊重,决策分为单目标决策和多目标决策。最后则是方案的实施和观察,这一步则是把我们的建立的模型和根据模型做出的结果应用到现实生活中去,如果一切正常,并且在未来我们所经历的事情恰好就是我们模型所预见的那样,那么这个模型可以继续使用。如果存在较大的偏差,则需要去发现是哪里出现了问题,一般主要的问题来自于问题的定义、问题的假设、数据的收集、环境变量的估计、以及最重要的模型的建立,我们需要逐一排查,发现问题后,需要重新再来一遍这样的流程。
幸运的是,大多数的数学建模工作是到不了这一步的,我们不需要担心我们的工作前功尽弃。一般在做完敏感性分析之后,便永远地躺在论文里。只有极少数优秀的、并且实用的模型,才有机会放在决策者的桌上,供决策者选择并且应用。这里需要注意的是,目前可能应用在实际生活中的模型,可能并不是这个世界上最先进、最好用的模型,但一定是经过了时间的洗礼,默默无闻地帮助了成千上万的人。
以上,便是对数学建模的过程(生命周期)进行了一个较为完整清晰的叙述,下面我们来谈一谈第二个议题,即它可以解决哪些问题。
2. 数学建模可以解决哪些问题?实际上我觉得这个问题太大了,我没有资格来回答这个问题,因为说句实话,随着数学、统计学和计算机科学的蓬勃发展,基本上每一门学科都开始或者尝试开始使用数学建模的方法研究本学科。在宏观的学科上,比如自然科学(数学、物理学、化学、生命科学、计算机科学、环境科学、地球科学、心理与认知科学等)、工程学(电子工程、电气工程、机械工程、土木工程、软件工程、汽车工程、人工智能、材料科学与工程等)、社会科学(政治学、经济学、管理学、教育学、社会学等)其中都有数学建模的影子,比如某门学科前面带上计算、计量、信息、分析、优化、运筹、统计这样词汇的学科或科目,一般都涉及了数学建模。比如计算物理、计算化学、计算数学、生物信息学、计量经济学、商业分析等。对于不同专业的同学对于数学建模的理解深度需要不同,我可以做个恰当的比喻。学数学的同学,需要会造锤子,也会使用锤子,并且造锤子的时间可能比使用锤子的时间多很多。广大理工科专业的同学,需要看过造锤子,但是自己只要会用锤子就行了,并且应该是最会使用锤子的一类人。广大社会科学专业的同学,只需要使用锤子,并且只是偶尔使用锤子就行了。
如果大家想要了解一些数学建模较为简单的案例,可以买一本书,这本书是姜启源和谢金星老师所写,叫做《数学模型》(第五版) ,这本书也可以基本上认为是全国大学生数学建模竞赛的半官方读物。如果用心阅读此书,并且在参加数学建模竞赛,尤其是全国大学生数学建模竞赛中,这本书一定要备在身上,比如在2017年国赛A题和2019年国赛A题的问题,有一定程度上参考这本书上的模型。比如这本书第六章代数方程与差分方程模型中的CT技术的图像与重建,就是2017年国赛A题的最基础的模型,在这本书的基础之上进行学习和文献查阅,会提高很多效率。还有第五章中的香烟过滤嘴的作用,可以类比2019年高压油管的模型建立。所以不管是从感兴趣的角度还是从比赛功利的角度,这本书都是值得学习一下的。下面我把这本书的目录给大家搬运一下,参与过数学建模竞赛的同学们,应该会看到很多熟悉的影子:
第一章 建立数学模型
1.1从现实对象到数学模型
1.2数学建模的重要意义
1.3建模示例之一包饺子中的数学
1.4建模示例之二路障间距的设计
1.5建模示例之三椅子能在不平的地面上放稳吗
1.6数学建模的基本方法和步骤
1.7数学模型的特点和分类
1.8怎样学习数学建模——学习课程和参加竞赛
第二章 初等模型
2.1双层玻璃窗的功效
2.2划艇比赛的成绩
2.3实物交换
2.4汽车刹车距离与道路通行能力
2.5估计出租车的总数
2.6评选举重总冠军
2.7解读CPI
2.8核军备竞赛
2.9扬帆远航
2.10节水洗衣机
第三章 简单优化模型
3.1存贮模型
3.2森林救火
3.3倾倒的啤酒杯
3.4铅球掷远
3.5不买贵的只买对的
3.6血管分支
3.7冰山运输
3.8影院里的视角和仰角
3.9易拉罐形状和尺寸的最优设让
第四章 数学规划模型
4.1奶制品的生产与销售
4.2自来水输送与货机装运
4.3汽车生产与原油采购
4.4接力队选拔和选课策略
4.5饮料厂的生产与检修
4.6钢管和易拉罐下料
4.7广告投入与升级调薪
4.8投资的风险与收益
第五章 微分方程模型
5.1人口增长
5.2药物中毒急救
5.3捕鱼业的持续收获
5.4资金、劳动力与经济增长
5.5香烟过滤嘴的作用
5.6火箭发射升空
5.7食饵与捕食者模型
5.8赛跑的速度
5.9万有引力定律的发现
5.10传染病模型和SARS的传播
第六章 代数方程与差分方程模型
6.1投入产出模型
6.2CT技术的图像重建
6.3原子弹爆炸的能量估计与量纲分析
6.4市场经济中的蛛网模型
6.5减肥计划——节食与运动
6.6按年龄分组的人口模型
第七章 离散模型
7.1汽车选购
7.2职员晋升
7.3厂房新建还是改建
7.4循环比赛的名次
7.5公平的席位分配
7.6存在公平的选举吗
7.7价格指数
7.8钢管的订购和运输
第八章 概率模型
8.1传送系统的效率
8.2报童的诀窍
8.3航空公司的超额售票策略
8.4作弊行为的调查与估计
8.5轧钢中的浪费
8.6博彩中的数学
8.7钢琴销售的存贮策略
8.8基因遗传
8.9自动化车床管理
第九章 统计模型
9.1孕妇吸烟与胎儿健康
9.2软件开发人员的薪金
9.3酶促反应
9.4投资额与生产总值和物价指数
9.5冠心病与年龄
9.6鲸虫分类判别
9.7学生考试成绩综合评价
9.8艾滋病疗法的评价及疗效的预测
第十章 博弈模型
10.1点球大战
10.2拥堵的早高峰
10.3“一口价”的战略
10.4不患寡而患不均
10.5效益的合理分配
10.6加权投票中权力的度量
通过这本书我们可以看到数学建模在各个领域的简单应用,至于更深层次的应用,我觉得各行业的从业者,都可以单独开一个新的问题进行讨论了。在教学的环节中,能理解到上述层次一般上是够用了。下面回答最后一个,也是最为使用的问题:目前有哪些和数学建模相关的竞赛?
3. 目前有哪些和「数学建模」相关的竞赛?这是一个非常好的问题,也应该是这篇回答最为实用的问题,作为一名学科竞赛指导老师,在这个领域有自己的心得体会。目前由于人工智能和数学建模是强相关,本质上人工智能的分支是很多统计模型的合集。因此这一两年数学建模类的竞赛越来越火热。我把数学建模竞赛主要分为三类:
- 直接冠以「数学建模」在竞赛名字上的比赛,也就是狭义数学建模竞赛。
- 与数学建模间接相关的比赛,如人工智能、数据分析等竞赛平行竞赛,以及将数学建模利用到自己各个专业中的比赛,如iGEM,以及各种创新创业类、学术作品比赛中间接用到数学建模方法的,如挑战杯、互联网 、节能减排等,这我将其称为广义数学建模竞赛。
一般我们大多数学生参加的数学建模竞赛为狭义数学建模竞赛,我一篇文章数学建模竞赛的一些心得体会(关于每年的比赛) 中有对一年所有狭义的数学建模竞赛进行梳理和难度分析。这里我仅列举我国官方组织举办的数学建模竞赛 :
1.全国大学生数学建模竞赛(简称国赛)
2.“深圳杯”数学建模挑战赛(简称深圳杯)
3.中国研究生数学建模竞赛(简称研赛)
以上是我们我们国家官方组织举办的比赛,特别注意的是国赛和研赛在上海市落户加分中是被认可的。国赛是目前发展最完善、影响力最大、参与人数最广、并且规则最为严格的比赛。深圳杯是一个竞争最为激烈,参赛周期最长,含金量最高,并且在一定程度上解决实际问题的比赛。想要学习数学建模或者查阅数学建模优秀论文,可以去中国大学生在线-数学建模板 块进行学习。研赛也是是目前研究生参与人数最多的比赛之一。
除了大学生和研究生的数学建模竞赛,高中生的数学建模竞赛也有一定程度的发展,分别是丘成桐科学奖和美国高中生数学建模竞赛,由于参与人数较少,并且高中生的知识储备大多不足,并且大多精力有限,这里不展开介绍。
关于广义数学建模竞赛,真的是无穷无尽的。我觉得现在凡是挂上人工智能、数据分析、数据挖掘等名头的都可以算作这一类比赛,由于比赛很多,我在知乎上找了一个不错的问题:国内外有哪些数据分析相关的竞赛比赛网站? ,大家可以进行参考。
关于自己各个学科、各个领域的学习(竞赛)中,大家在参与的时候,不妨思考下,到底能不能用到数学建模的相关知识,是一定要用?还是用了之后会锦上添花?
这个问题,我想在本回答的最后,留给各大读者朋友们!大家可以在评论区进行留言,一起讨论。
如果喜欢,欢迎点赞 收藏哦~