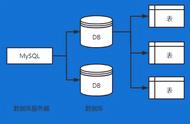
ShardingSphere 读写分离方案[1](摘自 shardingsphere 官网)
ShardingSphere[2] 的读写分离主要依赖内核的相关功能。包括解析引擎和路由引擎。解析引擎将用户的 SQL 转化为 ShardingSphere 可以识别的 Statement 信息,路由引擎根据 SQL 的读写类型以及事务的状态来做 SQL 的路由。如下图所示,ShardingSphere 识别到读操作和写操作,分别会路由至不同的数据库实例。

MSE 提供了一种动态数据流量治理的方案,您可以在不需要修改任何业务代码的情况下,实现数据库的读写分离能力。下面介绍 MSE 基于 Mysql 数据存储通过的读写分离能力。
前提条件
- 应用接入 MSE
- 部署 Demo 应用
在阿里云容器服务中部署 A、B、C 三个应用,并且将应用均接入 MSE 服务治理[3],用于增加具备数据库治理能力的 Agent。

- 创建 RDS 只读实例[4]
我们需要创建 RDS 只读实例,利用只读实例满足大量的数据库读取需求,增加应用的吞吐量。
配置读写分离规则
- 我们需要配置以下环境变量来额外开启/配置数据库的读写分离能力

- 我们可以通过控制台配置弱读请求的规则或者指定某些接口为弱读请求
apiVersion: database.opensergo.io/v1alpha1
kind: AccessControlRule
metadata:
name: read-only-control-rule
labels:
app: foo
spec:
selector:
app: foo
target:
- resource:
path: '/getLocation'
controlStrategies:
weak: true
上述 OpenSergo 标准的规则表示 /getLocation 接口的请求为弱读请求。
我们针对一些大数据量查询、对延时不太敏感的业务请求可以配置为 weak 类型
SQL 洞察
如上只需轻松的两步我们就实现了数据库的读写分离能力。基于数据库读写分离能力,配合 MSE 数据库治理的 SQL 洞察我们可以快速定位 RT 过大的查询请求,帮助我们进一步分析 SQL 对我们数据库稳定性的影响。