时钟频率
炒作内存时钟频率是厂家常用的营销手段,他们宣传内存越快越好,实际上真的是这样吗?
知名数码博主Linus Tech Tips解答了这个问题:厂商会引诱你购买“更快”的RAM,实际上却几乎没有性能提升。
内存频率和数据转移到显存的速度无关,提高频率最多只能有3%的性能提升,你还是把钱花在其他地方吧!
内存容量
内存大小不会影响深度学习性能,但是它可能会影响你执行GPU代码的效率。内存容量大一点,CPU就可以不通过磁盘,直接和GPU交换数据。
所以用户应该配备与GPU显存匹配的内存容量。如果有一个24GB显存的Titan RTX,应该至少有24GB的内存。但是,如果有更多的GPU,则不一定需要更多内存。
Tim认为:内存关系到你能不能集中资源,解决更困难的编程问题。如果有更多的内存,你就可以将注意力集中在更紧迫的问题上,而不用花大量时间解决内存瓶颈。
他还在参加Kaggle比赛的过程中发现,额外的内存对特征工程非常有用。
CPU过分关注CPU的性能和PCIe通道数量,是常见的认知误区。用户更需要关注的是CPU和主板组合支持同时运行的GPU数量。

CPU和PCIe
人们对PCIe通道的执念近乎疯狂!而实际上,它对深度学习性能几乎没有影响。
如果只有一个GPU,PCIe通道的作用只是快速地将数据从内存传输到显存。
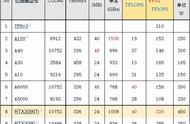
ImageNet里的32张图像(32x225x225x3)在16通道上传输需要1.1毫秒,在8通道上需要2.3毫秒,在4通道上需要4.5毫秒。
这些只是是理论数字,实际上PCIe的速度只有理论的一半。PCIe通道通常具有纳秒级别的延迟,因此可以忽略延迟。
Tim测试了用32张ImageNet图像的mini-batch,训练ResNet-152模型所需要的传输时间:
- 前向和后向传输:216毫秒
- 16个PCIe通道CPU-> GPU传输:大约2毫秒(理论上为1.1毫秒)
- 8个PCIe通道CPU-> GPU传输:大约5毫秒(2.3毫秒)
- 4个PCIe通道CPU-> GPU传输:大约9毫秒(4.5毫秒)
因此,在总用时上,从4到16个PCIe通道,性能提升约3.2%。但是,如果PyTorch的数据加载器有固定内存,则性能提升为0%。因此,如果使用单个GPU,请不要在PCIe通道上浪费金钱。
在选择CPU PCIe通道和主板PCIe通道时,要保证你选择的组合能支持你想要的GPU数量。如果买了支持2个GPU的主板,而且希望用上2个GPU,就要买支持2个GPU的CPU,但不一定要查看PCIe通道数量。

PCIe通道和多GPU并行计算
如果在多个GPU上训练网络,PCIe通道是否重要呢?Tim曾在ICLR 2016上发表了一篇论文指出(https://arxiv.org/abs/1511.04561):如果你有96个GPU,那么PCIe通道非常重要。
但是,如果GPU数量少于4个,则根本不必关心PCIe通道。几乎很少有人同时运行超过4个GPU,所以不要在PCIe通道上花冤枉钱。这不重要!
CPU核心数
为了选择CPU,首先需要了解CPU与深度学习的关系。
CPU为深度学习中起到什么作用?当在GPU上运行深度网络时,CPU几乎不会进行任何计算。CPU的主要作用有:(1)启动GPU函数调用(2)执行CPU函数。
到目前为止,CPU最有用的应用是数据预处理。有两种不同的通用数据处理策略,具有不同的CPU需求。
第一种策略是在训练时进行预处理,第二种是在训练之前进行预处理。
对于第一种策略,高性能的多核CPU能显著提高效率。建议每个GPU至少有4个线程,即为每个GPU分配两个CPU核心。Tim预计,每为GPU增加一个核心 ,应该获得大约0-5%的额外性能提升。
对于第二种策略,不需要非常好的CPU。建议每个GPU至少有2个线程,即为每个GPU分配一个CPU核心。用这种策略,更多内核也不会让性能显著提升。
CPU时钟频率
4GHz的CPU性能是否比3.5GHz的强?对于相同架构处理器的比较,通常是正确的。但在不同架构处理器之间,不能简单比较频率。CPU时钟频率并不总是衡量性能的最佳方法。
在深度学习的情况下,CPU参与很少的计算:比如增加一些变量,评估一些布尔表达式,在GPU或程序内进行一些函数调用。所有这些都取决于CPU核心时钟率。
虽然这种推理似乎很明智,但是在运行深度学习程序时,CPU仍有100%的使用率,那么这里的问题是什么?Tim做了一些CPU的降频实验来找出答案。
CPU降频对性能的影响:

请注意,这些实验是在一些“上古”CPU(2012年推出的第三代酷睿处理器)上进行的。但是对于近年推出的CPU应该仍然适用。
硬盘/固态硬盘(SSD)通常,硬盘不会限制深度学习任务的运行,但如果小看了硬盘的作用,可能会让你追、悔、莫、及。
想象一下,如果你从硬盘中读取的数据的速度只有100MB/s,那么加载一个32张ImageNet图片构成的mini-batch,将耗时185毫秒。
相反,如果在使用数据前异步获取数据,将在185毫秒内加载这些mini-batch的数据,而ImageNet上大多数神经网络的计算时间约为200毫秒。所以,在计算状态时加载下一个mini-batch,性能将不会有任何损失。
Tim小哥推荐的是固态硬盘(SSD),他认为SSD在手,舒适度和效率皆有。和普通硬盘相比,SSD程序启动和响应速度更快,大文件的预处理更是要快得多。
顶配的体验就是NVMe SSD了,比一般SSD更流畅。