只要拿到这个配置你就可以导入别人的 sitemap

Selector
直译起来是选择器,从一个布满数据的 HTML 页面中去取出数据,就需要选择器去定位我们的数据的具体位置。
每一个 Selector 可以获取一个数据,要取多个数据就需要定位多个 Selector。
Web Scraper 提供的 Selector 有很多,但本篇文章只介绍几种使用频率最高,覆盖范围最广的 Selector,了解了一两种之后,其他的原理大同小异,私下再了解一下很快就能上手。

Web Scraper 使用的是 CSS 选择器来定位元素,如果你不知道它,也无大碍,在大部分场景上,你可以直接用鼠标点选的方式选中元素, Web Scraper 会自动解析出对应的 CSS 路径。
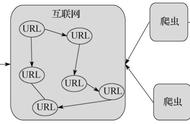
Selector 是可以嵌套的,子 Selector 的 CSS 选择器作用域就是父 Selector。
正是有了这种无穷无尽的嵌套关系,才让我们可以递归爬取整个网站的数据。
如下就是后面我们会经常放的 选择器拓扑,利用它可以直观的展示 Web Scraper 的爬取逻辑

数据爬取与导出
在定义好你的 sitemap 规则后,点击 Scrape 就可以开始爬取数据。
爬取完数据后,不会立马显示在页面上,需要你再手动点击一下 refresh 按钮,才能看到数据。
最后数据同样是可以导出为 csv 或者 xlsx 文件。