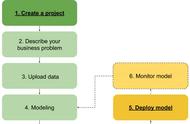
2.4 模型训练
模型训练是选择模型学习数据分布的过程。这过程还需要依据训练结果调整算法的(超)参数,使得结果变得更加优良。
- 2.4.1 数据集划分训练模型前,一般会把数据集分为训练集和测试集,并可再对训练集再细分为训练集和验证集,从而对模型的泛化能力进行评估。① 训练集(training set):用于运行学习算法。② 开发验证集(development set)用于调整参数,选择特征以及对算法其它优化。常用的验证方式有交叉验证Cross-validation,留一法等;③ 测试集(test set)用于评估算法的性能,但不会据此改变学习算法或参数。
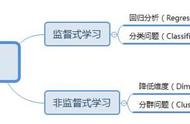
- 2.4.2 模型选择常见的机器学习算法如下:模型选择取决于数据情况和预测目标。可以训练多个模型,根据实际的效果选择表现较好的模型或者模型融合。

模型选择
- 2.4.3 模型训练训练过程可以通过调参进行优化,调参的过程是一种基于数据集、模型和训练过程细节的实证过程。超参数优化需要基于对算法的原理的理解和经验,此外还有自动调参技术:网格搜索、随机搜索及贝叶斯优化等。
模型评估的标准:模型学习的目的使学到的模型对新数据能有很好的预测能力(泛化能力)。现实中通常由训练误差及测试误差评估模型的训练数据学习程度及泛化能力。
- 2.5.1 评估指标① 评估分类模型:常用的评估标准有查准率P、查全率R、两者调和平均F1-score 等,并由混淆矩阵的统计相应的个数计算出数值:混淆矩阵查准率是指分类器分类正确的正样本(TP)的个数占该分类器所有预测为正样本个数(TP FP)的比例;查全率是指分类器分类正确的正样本个数(TP)占所有的正样本个数(TP FN)的比例。F1-score是查准率P、查全率R的调和平均:② 评估回归模型:常用的评估指标有RMSE均方根误差 等。反馈的是预测数值与实际值的拟合情况。③ 评估聚类模型:可分为两类方式,一类将聚类结果与某个“参考模型”的结果进行比较,称为“外部指标”(external index):如兰德指数,FM指数 等;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”(internal index):如紧凑度、分离度 等。
- 2.5.2 模型评估及优化根据训练集及测试集的指标表现,分析原因并对模型进行优化,常用的方法有:
决策是机器学习最终目的,对模型预测信息加以分析解释,并应用于实际的工作领域。
需要注意的是工程上是结果导向,模型在线上运行的效果直接决定模型的成败,不仅仅包括其准确程度、误差等情况,还包括其运行的速度(时间复杂度)、资源消耗程度(空间复杂度)、稳定性的综合考虑。
参考文献:《机器学习》周志华
《统计学习方法》李航
Google machine-learning
,