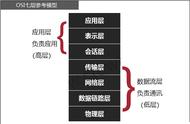
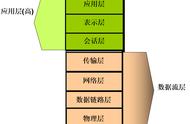
(左边:互联网诞生前——美国的电话网络 右边:兰德公司的“Baran 方案”)
有了兰德公司的方案,美国军方找到当时最大的电信公司 AT&T,想要实现这个系统,结果被否决了。AT&T 高层认为:搞这样一种系统根本不切实际。于是 Baran 的方案中途夭折。
为啥 AT&T 反对这个方案捏?一方面,成功的大公司总是有很强的思维定势(关于这点,参见这篇文章);另一方面,Baran 的设计方案确实很超前——其前瞻性不仅包括“拓扑结构”,而且把当时电信行业的几大核心观念完全颠覆掉了(具体如何颠覆,后续章节还会再聊)。
时间一晃又过了好多年,到了60年代末,由于一系列机缘巧合,英国佬发现了“Baran 方案”的价值,并据此搞了一个小型的 NPL 网络(NPL 是“国家物理实验室”的缩写)。然后在某次 ACM 会议上,美国佬看到英国佬的论文,才意识到:Baran 方案完全可行。经历了“出口转内销”的命运之后,该方案重新被美国国防部重视。之后,(国防部下属的)“高级计划研究局”(ARPA)开始筹建“阿帕网”(ARPANET),才有了如今的互联网。
聊完“拓扑”,再来聊“路由”。
当主机 A 向主机 B 发送网络层的数据时,大致会经历如下步骤:
1.
A 主机的协议栈先判断“A B 两个地址”是否在同一个子网(“子网掩码”就是用来干这事儿滴)。
如果是同一个子网,直接发给对方;如果不是同一个子网,发给本子网的【默认网关】。
(此处所说的“网关”指“3层网关/网络层网关”) 2.
对于“默认网关”,有可能自己就是路由器;也可能自己不是路由器,但与其它路由器相连。
也就是说,“默认网关”要么自己对数据包进行路由,要么丢给能进行路由的另一台设备。
(万一找不到能路由的设备,这个数据就被丢弃,于是网络通讯出错)
3.
当数据到达某个路由器之后,有如下几种可能——
3.1
该路由器正好是 B 所在子网的网关(与 B 直连),那就把数据包丢给 B,路由过程就结束啦;
3.2
亦或者,路由器会把数据包丢给另一个路由器(另一个路由器再丢给另一个路由器) …… 如此循环往复,最终到达目的地 B。
3.3
还存在一种可能性:始终找不到“主机 B”(有可能该主机“断线 or 关机 or 根本不存在”)。为了避免数据包长时间在网络上闲逛,还需要引入某种【数据包存活机制】(洋文叫做“Time To Live”,简称 TTL)。
通常会采用某个整数(TTL 计数)表示数据包能活多久。当主机 A 发出这个数据包的时候,这个“TTL 计数”就已经设置好了。每当这个数据包被路由器转发一次,“TTL 记数”就减一。当 TTL 变为零,这个数据包就死了(被丢弃)。
对于某些大型的复杂网络(比如互联网),每个路由器可能与其它 N 个路由器相连(N 可能很大)。对于上述的 3.2 情形,它如何判断:该转发给谁捏?
这时候,“路由算法”就体现出价值啦——
一般来说,路由器内部会维护一张【路由表】。每当收到一个网络层的数据包,先取出数据包中的【目标地址】,然后去查这张路由表,看谁距离目标最近,就把数据包转发给谁。
上面这段话看起来好像很简单,其实路由算法挺复杂滴。考虑到本文是“扫盲性质”,而且篇幅已经很长,不可能再去聊“路由算法”的细节。对此感兴趣的同学,可以去看《计算机网络》的第5章。
(技术菜鸟可以跳过这个小节)
由于互联网的 IP 协议已经成为“网络层协议”的事实标准,我简单聊一下互联网的路由机制是如何进化滴。
第1阶段:静态全局路由表
(前面说了)互联网的前身是“阿帕网/ARPANET”。在阿帕网诞生初期(上世纪70年代),全球的主机很少。因此,早期的路由表很简单,既是“全局”滴,又是“静态”滴。简而言之,每个路由器内部都维护一张“全局路由表”,这个“路由表”包含了全球所有其它路由器的关联信息。每当来了一个数据包,查一下这张全局路由表,自然就清楚要转发给谁,才能最快到达目的地。
早期的阿帕网,主机的变化比较少,也很少增加路由器。每当出现一个新的路由器,其它路由器的管理员就手工编辑各自的“全局路由表”。
为了加深大伙儿印象,特意找来两张70年代初的阿帕网拓扑图(注:图中的 IMP 是“Interface Message Processor”的缩写,也就是如今所说的“路由器”)。

(1973年的阿帕网)

(1977年的阿帕网)
第2阶段:动态全局路由表
后来,“阿帕网/互联网”的规模猛增,路由器数量也跟着猛增,隔三差五都有新的路由器冒出来。再用“静态路由表”这种机制,(编辑路由表的)管理员会被活活累死。于是改用“动态路由表”,并引入某种“路由发现机制”。但“路由表”依然是【全局】滴。
第3阶段:动态分级路由表
再到后来,全球的路由器越来越多,成千上万,再搞“全局路由表”已经不太现实了——
一方面,“全局路由表”越来越大(查询的速度就越来越慢)
另一方面,由于互联网的流量越来越大,每来一个数据包都要查表,查询越来越频繁。
于是,路由器开始吃不消了。为了解决困境,想出一个新招数:引入“分级路由”(hierarchical routing)。所谓的“分级路由”就是:把整个互联网分为多个大区域,每个大区域内部再分小区域,小区域内部再分小小区域 …… 看到这里,熟悉“数据结构与算法”的同学就会意识到——这相当于构造了一个【树状】层次结构。
有了这个层次结构,每个路由器重点关注:自己所在的那个最小化区域里面的网络拓扑。如此一来,每个路由器的“路由表”都会大幅度减小。

(全局路由表 VS 分级路由表)
◇互联网的路由——从“CAS”的角度看其健壮性如果把互联网视作一个系统,每个公网上的路由器都是一个自适应的主体。假如某个地区的网络流量突然暴涨,骨干网路由器会自动分流;假如因为地震或War,导致某个地区的骨干网路由器全部下线,周边地区的路由器也会自动避开这个区域 …..
所有这些工作,【不需要】依靠任何最高指挥中枢,去进行协调。
相反,如果互联网的路由系统中,设立了某种“Center委员会”进行实时调度,那互联网早就完蛋了,根本无法成长为今天这种规模。
(技术菜鸟可以跳过这个小节)
前面聊“互联网诞生”,说到兰德公司的“Baran 方案”。该方案对当时的电信系统提出几大革命性的变化,其中之一就是“分组交换”技术(也称“数据包交换”or“封包交换”)。
一般来说,网络层的设计有两种截然不同的风格:【电路交换 VS 分组交换】。有时候也分别称之为“有连接的网络层 VS 无连接的网络层”。此处所说的“连接”指的是某种“虚电路”(洋文叫做“virtual circuit”,简称 VC)。
要理解“虚电路”,首先要从老式的电话系统说起。
最早期的电话,既没有拨号盘也没有按键,全靠一张嘴。当你拿起电话,先告诉接线员你要打给谁,接线员会用一根跳接线,插入电话交换设备的某个插孔,从而把你的电话机与对方的电话机相连。于是建立了一条两人之间的电话通路,也就是“电路”。你可以把“接线员”想象成某种“人肉路由器” :)