一致性hash论文
一句话概括一致性哈希:就是普通取模哈希算法的改良版,哈希函数计算方法不变,只不过是通过构建环状的 Hash 空间代替普通的线性 Hash 空间。具体做法如下:
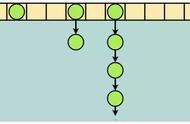
首先,选择一个足够大的Hash空间(一般是 0 ~ 2^32)构成一个哈希环。

一致性哈希环
然后,对于缓存集群内的每个存储服务器节点计算 Hash 值,可以用服务器的 IP 或 主机名计算得到哈希值,计算得到的哈希值就是服务节点在 Hash 环上的位置。

节点哈希
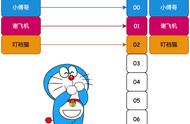
最后,对每个需要存储的数据 key 同样也计算一次哈希值,计算之后的哈希也映射到环上,数据存储的位置是沿顺时针的方向找到的环上的第一个节点。下图举例展示了节点存储的数据情况,我们下面的说明也是基于目前的存储情况来展开。

image
原理讲完了,来看看为什么这样的设计能解决上面普通哈希的两个问题。
扩展能力提升前面我们分析过,普通哈希算法当需要扩容增加服务节点的时候,会导致原油哈希映射大面积失效。现在,我们来看下一致性哈希是如何解决这个问题的。
如下图所示,当缓存服务集群要新增一个节点node3时,受影响的只有 key3 对应的数据 value3,此时只需把 value3 由原来的节点 node0 迁移到新增节点 node3 即可,其余节点存储的数据保持不动。