07:52:04.010 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
07:52:04.016 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:苗苗
07:52:04.016 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 数据结构:{01=花花, 12=苗苗, 05=豆豆, 09=蛋蛋}
Process finished with exit code 0
- 从测试结果可以看到,杜鹃散列可以通过两个散列函数解决索引冲突问题。不过这个探测的过程比较耗时。
说明:跳房子散列是一种基于开放寻址的算法,它结合了杜鹃散列、线性探测和链接的元素,通过桶邻域的概念——任何给定占用桶周围的后续桶,也称为“虚拟”桶。 该算法旨在在哈希表的负载因子增长超过 90% 时提供更好的性能;它还在并发设置中提供了高吞吐量,因此非常适合实现可调整大小的并发哈希表。
public boolean insert(AnyType x) {
if (!isEmpty()) {
return false;
}
int currentPos = findPos(x);
if (currentPos == -1) {
return false;
}
if (array[currentPos] != null) {
x = array[currentPos].element;
array[currentPos].isActive = true;
}
String hope;
if (array[currentPos] != null) {
hope = array[currentPos].hope;
x = array[currentPos].element;
} else {
hope = "10000000";
}
array[currentPos] = new HashEntry<>(x, hope, true);
theSize ;
return true;
}

- 该算法使用一个包含n 个桶的数组。对于每个桶,它的邻域是H个连续桶的小集合(即索引接近原始散列桶的那些)。邻域的期望属性是在邻域的桶中找到一个项目的成本接近于在桶本身中找到它的成本(例如,通过使邻域中的桶落在同一缓存行中)。在最坏的情况下,邻域的大小必须足以容纳对数个项目(即它必须容纳 log( n ) 个项目),但平均只能是一个常数。如果某个桶的邻域被填满,则调整表的大小。
测试
@Test
public void test_hashMap06() {
HashMap06ByHopscotchHashing<Integer> map = new HashMap06ByHopscotchHashing<>();
map.insert(1);
map.insert(5);
map.insert(9);
map.insert(12);
logger.info("数据结构:{}", map);
}

17:10:10.363 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 数据结构:HashMap{tab=[null,{"element":1,"hope":"11000000","isActive":true},{"element":9,"hope":"00000000","isActive":true},null,{"element":12,"hope":"10000000","isActive":true},{"element":5,"hope":"10000000","isActive":true},null,null]}
Process finished with exit code 0
- 通过测试可以看到,跳房子散列会在其原始散列数组条目中找到,或者在接下来的H-1个相邻条目之一找到对应的冲突元素。
说明:罗宾汉哈希是一种基于开放寻址的冲突解决算法;冲突是通过偏向从其“原始位置”(即项目被散列到的存储桶)最远或最长探测序列长度(PSL)的元素的位移来解决的。
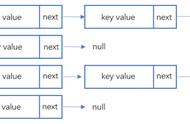
public void put(K key, V value) {
Entry entry = new Entry(key, value);
int idx = hash(key);
// 元素碰撞检测
while (table[idx] != null) {
if (entry.offset > table[idx].offset) {
// 当前偏移量不止一个,则查看条目交换位置,entry 是正在查看的条目,增加现在搜索的事物的偏移量和 idx
Entry garbage = table[idx];
table[idx] = entry;
entry = garbage;
idx = increment(idx);
entry.offset ;
} else if (entry.offset == table[idx].offset) {
// 当前偏移量与正在查看的检查键是否相同,如果是则它们交换值,如果不是,则增加 idx 和偏移量并继续
if (table[idx].key.equals(key)) {
// 发现相同值
V oldVal = table[idx].value;
table[idx].value = value;
} else {
idx = increment(idx);
entry.offset ;
}
} else {
// 当前偏移量小于我们正在查看的我们增加 idx 和偏移量并继续
idx = increment(idx);
entry.offset ;
}
}
// 已经到达了 null 所在的 idx,将新/移动的放在这里
table[idx] = entry;
size ;
// 超过负载因子扩容
if (size >= loadFactor * table.length) {
rehash(table.length * 2);
}
}

- 09、12 和 01 发生哈希索引碰撞,进行偏移量计算调整。通过最长位置探测碰撞元素位移来处理。
测试
public void test_hashMap07() {
Map<String, String> map = new HashMap07ByRobinHoodHashing<>();
map.put("01", "花花");
map.put("05", "豆豆");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
// 下标碰撞
map.put("09", "蛋蛋");
map.put("12", "苗苗");
logger.info("碰撞前 key:{} value:{}", "01", map.get("12"));
logger.info("数据结构:{}", map);
}