对于引入模型的自变量,通常没有个数要求。但从经验上看,不要一次性放入太多自变量。如果同时自变量太多,容易引起共线性问题。建议根据专业知识进行选择,同时样本量不能过少,通常要满足样本个数是自变量的20倍以上。
如果自变量为定类数据,需要对变量进行哑变量处理,可以在SPSSAU的【数据处理】→【生成变量】进行设置。具体设置步骤查看SPSSAU有关哑变量的文章:什么是虚拟变量?怎么设置才正确?

控制变量,可以是定量数据,也可以是定类数据。一般来说更多是定类数据,如:性别,年龄,工作年限等人口统计学变量。通常情况下,不需要处理,可以直接和自变量一起放入X分析框分析即可。
理论上,回归分析的因变量要求需服从正态分布,SPSSAU提供多种检验正态性的方法。

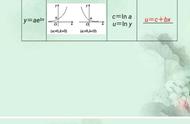
如果出现数据不正态,可以进行对数处理。若数据为问卷数据,建议可跳过正态性检验这一步。原因在于问卷数据属于等级数据,很难保证正态性,且数据本身变化幅度就不大,即使对数处理效果也不明显。
一般来说,回归分析之前需要做相关分析,原因在于相关分析可以先了解是否有关系,回归分析是研究有没有影响关系,有相关关系但并不一定有回归影响关系。当然回归分析之前也可以使用散点图查看数据关系。
操作
案例:在线英语学习购买因素研究
①操作步骤
将性别、年龄、月收入水平、产品、促销、渠道、价格、个性化服务、隐私保护共九个变量作为自变量,而将购买意愿作为因变量进行线性回归分析。
勾选“保存残差和预测值”。

②指标说明