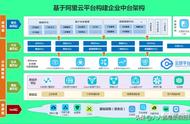
从下至上分为数据源层、数据集成服务层、工具支撑层、应用服务层、场景层。
数据源层:本层是各类数据的来源,包括公安内部的结构化和非结构化的数据,以及可以在业务支持下提供外部如互联网之类的数据等。
数据集成服务层包括数据接入管理,通过数据抽取的服务工具来对结构化和非结构化数据的抽取,在抽取的时候可以通过接入配置相关的功能来进行配置及抽取任务的管理,从而达到定时、定量的接入各类数据;数据处理,在系统中对于数据是实时接入的,在接入的同时也对数据进行了实时的处理。针对结构化数据我们进行了清洗和加工的操作,针对非结构化数据如图片,我们会做标注和特征提取的操作;数据管理,数据在入库以后,会进行统一的数据管理,在管理方面,包含了数据资产、数据维度、数据坐标、数据共享这几块的内容,通过这些方式,对数据进行全方位的掌控。
工具支撑层:提供知识图谱生成工具,可视化建模工具和关联关系分析工具,知识图谱是智能研判的核心内容,是构建以人为核心的相关业务,通过一系列的数据操作形成人员主题模型;同时通过模型管理、关系管理、标签管理来对人的相关业务数据进行管理。
应用服务层:体现了平台随想即成,随需而变的理念,在功能应用方面我们通过对公安业务的高度总结凝练,形成了信息查询、关系拓展、数据研判、实时监控、预测预警的功能应用服务体系,再结合各类可视化展示的相关功能,构建出了高效实用的应用服务模式。
场景层:用户的应用场景的无穷尽的,我们通过积累总结,针对用户的各种业务场景,推出了各种对应的业务模型,进一步形成了业务场景服务包,用时提供对外实时的模型服务,如实时预测、实时推送数据等。通过应用、API、服务、数据等方式来支撑我们自己产品的同时,也可以对外提供各种支持,如多终端的使用等。
2.7.2. 数据流程
平台数据整体逻辑针对行业数据管理的痛点,将数据由分散到集中,从无序到有组织,提供数据挖掘分析服务来针对业务场景进行数据价值挖掘,通过数据开放服务来支撑应用。
平台支持全生命周期的数据资管理,数据根据衍变过程可分为:基础数据 、主题数据、专题数据、接口数据。
基础数据:将分布在不同的业务系统的结构化和非结构化数据,通过ETL工具、API和MQ进行统一接入,形成基础数据。
主题数据:围绕人、物、地、事等基本业务要素,将基础数据进行组织,经过元数据管理、数据标准管理、数据质量管理等数据治理过程, 形成主题数据。
专题数据:通过数据增值服务,针对不同的应用场景进行数据挖掘,形成支撑场景业务的专题数据。通过标签服务生成的标签数据,通过数据建模生成的模型结果数据,通过知识图谱生成的关系图数据等。
接口数据:开放服务将数据转换成报文协议、流数据等接口数据,与业务应用进行对接。
2.8. 数据可视化平台2.8.1. 平台架构数据可视化平台为整个数据中台提供了大数据可视化展示能力,它为客户提供了各种可视化组件,客户可以根据自己的需求通过组件间简单组合进行数据展示。帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。

数据可视化平台通过三维表现技术来表示复杂的信息,实现对海量数据的立体呈现。可视化技术借助人脑的视觉思维能力,通过挖掘数据之间重要的关联关系将若干关联性的可视化数据进行汇总处理, 揭示数据中隐含的规律和发展趋势,从而提高数据的使用效率。在解决了海量数据分析耗时过长、挖掘深度不够、数据展现简单等问题的基础上,大数据可视化平台使人们不再局限于使用传统关系数据表来分析数据信息,而是以更直观的方式呈现和推导数据间的逻辑关系。 总而言之,数据可视化是做大数据分析的一个很重要的手段。
2.8.2. 数据流程
通过可视化分析展示平台,使抽象的数据信息变得简单、易懂,直观呈现数据分析结果,丰富的可视化组件可帮助业务准确的表达数据的价值所在,完善的功能可帮助用户建立有针对性的报表体系。其主要价值可体现在即席查询、数据洞察与大屏呈现、移动报表之上。
第三章 主要关键技术3.1. 内存级数据共享交换1) 多元异构、一键迀移
可实现多种数据库、多种数据结构的数据采集,具备可插拔的模板型数据接入方式。可同时实现结构化和非结构化数据的处理,实现对数据仓库、大数据平台以及各业务系统的数据,按照统一的传输交换策略进行高效传输和集中管理。
2) 数据采集和分发
适配多数据源,能够对结构化数据、半结构化数据、非结构化数 据的差异化数据源分别实现相应的数据采集能力。同时可实现跨网络的远程数据采集和传输到目标源数据库。
3) 实时数据交换
可实现实时数据获取、加载与对外交换,支持系统间实时批量数据交换,提高数据分析与使用的时效性。
4)数据ETL工作流
数据清洗,可实现关键业务数据的质量校验,清洗处理,转码要求等。数据拆分与合并,可实现大批量数据文件、数据库数据的增量甄别,全量合并推送等功能,提高数据交换效率。数据质量校验,可实现对加载的数据文件或者数据库数据进行质量校验,包括但不限于数据格式的准确性,数据表的非空校验,异常数据识别等。并根据安全要求,进行数据传输加密处理。
5)分布式内存处理
内置分布式缓存集群,集群规模可扩展到100个节点以上。可对流入的数据流进行实时数据清洗和加工,集群规模可根据待处理的数据量增长而扩大集群规模,可满足来自数据源的高并发写入和高吞吐写入,单节点写入数据量可达到500M/S以上。
6)多种数据灾备方式
支持多种备份和恢复方式
提供全量备份、增量备份、日志备份等备份方式,提供按照时间点恢复、自动灾难恢复等多种恢复方式。
支持数据库实时同步
支持主库与备份库实时同步、和按自定义时间戳或SCN号同步。支持数据库高可用容灾
通过平台内置的数据库日志采集模块,可实现将主库中的表数据实时同步到异地灾备中心。
3.2. 一站式数据集成及数据管理1) 全局规划一一全局设计大数据中心,标准模型设计,统一数据指标口径;
2) 数据融合一一打通任意数据源,自动重构元数据与主题数据,为应用提供统一数据服务;
3) 资产管理——对数据资产全局把控和智能管理,对数据高效治理,追踪数据用途和产生的价值;
4) 智能分析一一对所管理的数据进行机器学习算法分析,使统计分析的BI智能升华到AI智能;
5) 数据映射一一自动加速数据查询,最高可提速1000倍,完全发挥关系代数的计算能力;
6) 查询下推一一对任意数据源优化查询语义,如阿里云RDS、亚马逊 S3、RDBMS、NoSQL 数据库、Hadoop、Elastic Search 等;
7)统一查询引擎一一基于成本的查询规划器自动生成查询规划来优化数据映射和下推查询。
3.3. 数据分析模型平台需要支持不同的业务应用。为了使平台具有灵活性和扩展性,能够完成不同业务数据的处理,需要将数据处理的模型和算法独立出来,以适应不同的业务要求。在具体的实施中,依据大数据处理的目标定义和选择合适的数据处理模型。
平台通过管理各种数据分析模型,加载样本数据,创建调度任务, 产生中间或最终结果,提供给不同的应用系统或者用户进行访问、查询等。系统将采用具有国际标准的企业级的服务接口进行封装,从而能够满足不同的需求。平台通过基于Oozie工作流的方式,可视化的监控到每个分析模型的工作MR的运行情况,并且能够对分析模型进行评价和优化,这也是目前系统的创新点之一。
3.4. 数据治理技术数据治理是指从使用零散数据变为使用统一主数据、从具有很少或没有组织和流程治理到机构全业务范围内的综合数据治理、从尝试处理主数据混乱状况到主数据井井有条的一个过程。
大数据平台数据治理能力的建设,需要引入数据治理的核心思想和技术,从制度、标准、监控、流程几个方面提升开行的数据信息管理能力,解决目前所面临的数据标准问题、数据质量问题、元数据管理问题和数据服务问题。
(―)数据治理核心驱动力
数据标准规范化:规范化管理构成数据平台的业务和技术基础设施,包括数据管控制度与流程规范文档、信息项定义等。
数据关系脉络化:实现对数据间流转、依赖关系的影响和血缘分析。
数据质量度量化:全方位管理数据平台的数据质量,实现可定义的数据质量检核和维度分析,以及问题跟踪。
服务电子化:为数据平台提供面向业务用户的服务沟通渠道。
(二)数据治理核心技术
统一数据标准:对数据进行分类、口径、模型等规则的标准化统—管理
元数据管理:以建立企业级数据模型、指标体系为切入,将业务分类、业务规则、数据立方体纳入元数据管理
数据质量管理:建立跨专业、全过程的数据质量管理体系,保障数据信息的准确、规范、完整、一致
数据生命周期管理:实现数据生命周期的多级管理,将数据使用频度和资源占用合理分配
数据安全管控:对数据管理全过程的数据资产、传输、环境、访问控制、人员权限等方面进行全面的安全管控。
3.5. 数据挖掘技术数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、数据检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
从数据本身来考虑,通常数据挖掘需要有数据清理、数据变换、数据挖掘实施过程、模式评估和知识表示等8个步骤。
信息收集:根据确定的数据分析对象抽象出在数据分析中所需要的特征信息,然后选择合适的信息收集方法,将收集到的信息存入数据库。对于海量数据,选择一个合适的数据存储和管理的数据仓库是至关重要的。
数据集成:把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为组织提供全面的数据共享。
数据规约:执行多数的数据挖掘算法即使在少量数据上也需要很长的时间,而做商业运营数据挖掘时往往数据量非常大。数据规约技术可以用来得到数据集的规约表示,它小得多,但仍然接近于保持元数据的完整性,并且规约后执行数据挖掘结果与规约前执行结果相同或几乎相同。
数据清理:在数据库中的数据有一些是不完整的(有些感兴趣的属性缺少属性值),含噪声的(包含错误的属性值)并且是不一致的 (同样的信息不同的表示方式),因此需要进行数据清理,将完整、正确、一致的数据信息存入数据仓库中。不然,挖掘的结果会差强人
数据变换:通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。对于有些实数型数据,通过概念分层和数据的离散化来转换数据也是重要的一步。
数据挖掘过程:根据数据仓库中的数据信息,选择合适的分析工具,应用统计方法、事例推理、决策树、规则推理、模糊集、甚至神经网络、遗传算法的方法处理信息,得出有用的分析信息。
模式评估:从商业角度,由行业专家来验证数据挖掘结果的正确性。
知识库:将数据挖掘所得到的分析信息以可视化的方式呈现给用户,或作为新的知识存放在知识库中,供其他应用程序使用。
数据挖掘过程是一个反复循环的过程,每一个步骤如果没有达到预期目标,都需要回到前面的步骤,重新调整并执行。
3.6. 可视化建模技术可视化建模(VISUAL MODELING)是利用围绕现实想法组织模型 的一种思考问题的方法。模型对于了解问题、与项目相关的每个人(客 户、行业专家、分析师、设计者等)沟通、模仿企业流程、准备文档、设计程序和数据库来说都是有用的。建模促进了对需求的更好的理 解、更清晰的设计、更加容易维护的系统。可视化建模就是以图形 的方式描述所开发的系统的过程。可视化建模允许你提出一个复杂问 题的必要细节,过滤不必要的细节。它也提供了一种从不同的视角观 察被开发系统的机制。
3.7. NLP语义分析技术在语义理解领域的核心技术智慧语义认知技术是采用一种完全自主知识产权的创新方法,不同于深度学习的另一种途径,是基于概念识别的一种方法。从目前的效果来看,至少有三个不同于深度学习的特点:第一不需要GPU那么大的算力支持,传统的PC服务器就可以满足要求;第二不需要提供大量的语料来训练;第三对多语种的支持具备明显的便利性。
技术优势
核心技术聚焦在人工智能的语义认知方面和非结构化大数据分析挖掘方面。
在人工智能的语义认知方面,核心技术的创新性在于,(1)构建了基于概念的多层次语义知识表示方法和语义分析技术,解决自然语言中普遍存在的歧义性,超越关键字的领先语义理解技术,能实现对文本的多个层次(词语、句子、段落、篇章)的分析,实现文本语义的量化计算,提供强大的自然语言理解相关分析算法。(2)构建了多语种分析算法和机器翻译算法,解决多语种的语义认知问题,利用一套算法流程,实现多语种支持,语种扩展性好。新增加语种,不用修 改算法。(3)构建了智能机器人认知技术,基于概念计算和深度学习技术,实现了用户意图的识别、上下文会话识别、自学习机制等,解决了在没有大量语料训练的行业应用中的机器人交互效果差的问题。
非结构化大数据分析挖掘方面,核心技术的创新性在于,(1)构 建了 “本体〇-要素E-概念C”三位一体的本体建模技术,为业务人员提供形式化的业务建模工具,使得业务人员摆脱文本表示的多样性和歧义性带来的复杂算法,从自然语言处理算法直接应用到面向业务建模,实现业务高可配置性。(2)构建了良好的可扩展的分析挖掘平台,从单一语种的算法提供,到多语种算法的统一支持,同时支持包括深度学习、分布式计算等技术的集成。(3)构建了非结构化大数据 的分布式架构,支持卓越的大数据计算与存储平台集成能力,支持主流的 Hadoop 平台,支持 Map/Reduce 计算,支持 Spark、Storm、Kafka等分布式计算平台集成。
3.8. 知识图谱技术数据实时处理工具能够支持大规模的知识点间关联关系的计算,它能够支持百亿级关联规模的政务知识图谱管理,同时数据实时处理技术还为知识图谱计算系统在保证如此大规模的图谱知识管理下,提供了知识图谱实体及其关联更新速度达到毫秒级的保障,也确保知识图谱系统中实现了对知识图谱的星型查询速度能够达到秒级以上。
,