解决策略:
a.消息队列 异步重试
无论使用哪一种执行时序,可以在执行步骤1时,将步骤2的请求写入消息队列,当步骤2失败时,就可以使用重试策略,对失败操作进行“补偿”。

具体步骤如下:
把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka消息队列)
当删除缓存值或者是更新数据库值成功时,把这些值从消息队列中去除,以免重复操作。
当删除缓存值或者是更新数据库值失败时,执行失败策略,重试服务从消息队列中重新读取这些值,然后再次进行删除或更新。
删除或者更新失败时,需要再次进行重试,重试超过的一定次数。向业务层发送报错信息。
b.订阅Binlog变更日志
创建更新缓存服务,接收数据变更的MQ消息,然后消费消息,更新/删除redis中的缓存数据。
使用Binlog实时更新/删除Redis缓存。利用Canal,即将负责更新缓存的服务伪装成一个MySQL的从节点,从MySQL接收Binlog,解析Binlog之后,得到实时的数据变更信息,然后根据变更信息去更新/删除Redis缓存。
MQ Canal策略,将Canal Server接收到的Binlog数据直接投递到MQ进行解耦,使用MQ异步消费Binlog日志,以此进行数据同步。
不管用MQ/Canal或者MQ Canal的策略来异步更新缓存,对整个更新服务的数据可靠性和实时性要求都比较高,如果产生数据丢失或者更新延时情况,会造成MySQL和Redis中的数据不一致。因此,使用这种策略时,需要考虑出现不同步问题时的降级或补偿方案。
高并发情况
使用以上策略后,可以保证在单线程/无并发场景下的数据一致性。但是,在高并发场景下,由于数据库层面的读写并发,会引发的数据库与缓存数据不一致的问题(本质是后发生的读请求先返回了)
(1) 先删除缓存,再更新数据库
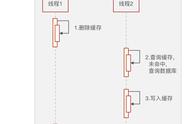
假设线程A删除缓存值后,由于网络延迟等原因导致未及更新数据库,而此时,线程B开始读取数据时会发现缓存缺失,进而去查询数据库。而当线程B从数据库读取完数据、更新了缓存后,线程A才开始更新数据库,此时,会导致缓存中的数据是旧值,而数据库中的是最新值,产生“数据不一致”。其本质就是,本应后发生的“B线程-读请求”先于“A线程-写请求”执行并返回了。

或者

解决策略:
设置缓存过期时间 延时双删
通过设置缓存过期时间,若发生上述淘汰缓存失败的情况,则在缓存过期后,读请求仍然可以从DB中读取最新数据并更新缓存,可减小数据不一致的影响范围。虽然在一定时间范围内数据有差异,但可以保证数据的最终一致性。
此外,还可以通过延时双删进行保障:在线程A更新完数据库值以后,让它先sleep一小段时间,确保线程B能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程A再进行删除。后续其它线程读取数据时,发现缓存缺失,会从数据库中读取最新值。
redis.delKey(X)db.update(X)Thread.sleep(N)redis.delKey(X)
sleep时间:在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,以此为基础来进行估算。