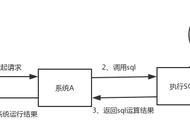
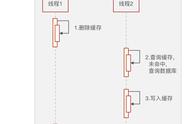
高并发情况
有四种场景会造成数据不一致:

针对场景1和2的解决方案是:保存请求对缓存的读取记录,延时消息比较,发现不一致后,做业务补偿 针对场景3和4的解决方案是:对于写请求,需要配合分布式锁使用。写请求进来时,针对同一个资源的修改操作,先加分布式锁,保证同一时间只有一个线程去更新数据库和缓存;没有拿到锁的线程把操作放入到队列中,延时处理。用这种方式保证多个线程操作同一资源的顺序性,以此保证一致性。

其中,分布式锁的实现可以使用以下策略:

上述策略只能保证数据的最终一致性。要想做到强一致,最常见的方案是2PC、3PC、Paxos、Raft这类一致性协议,但它们的性能往往比较差,而且这些方案也比较复杂,还要考虑各种容错问题。如果业务层要求必须读取数据的强一致性,可以采取以下策略:
暂存并发读请求
在更新数据库时,先在Redis缓存客户端暂存并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性。
串行化
读写请求入队列,工作线程从队列中取任务来依次执行
修改服务Service连接池,id取模选取服务连接,能够保证同一个数据的读写都落在同一个后端服务上。
修改数据库DB连接池,id取模选取DB连接,能够保证同一个数据的读写在数据库层面是串行的。
使用Redis分布式读写锁
将淘汰缓存与更新库表放入同一把写锁中,与其它读请求互斥,防止其间产生旧数据。读写互斥、写写互斥、读读共享,可满足读多写少的场景数据一致,也保证了并发性。并根据逻辑平均运行时间、响应超时时间来确定过期时间。
public void write { lock writeLock = redis.getWriteLock(lockKey); writeLock.lock; try { redis.delete(key); db.update(record); } finally { writeLock.unlock; }}public void read { if (caching) { return; } // no cache Lock readLock = redis.getReadLock(lockKey); readLock.lock; try { record = db.get; } finally { readLock.unlock; } redis.set(key, record);}(四)小结