编译自: https://linuxhandbook.com/Sed-reference-guide/
作者: Sylvain Leroux
译者: qhwdw
在前面的文章中,我展示了 Sed 命令的基本用法 , Sed 是一个实用的流编辑器。今天,我们准备去了解关于 Sed 更多的知识,深入了解 Sed 的运行模式。这将是你全面了解 Sed 命令的一个机会,深入挖掘它的运行细节和精妙之处。因此,如果你已经做好了准备,那就打开终端吧, 下载测试文件 然后坐在电脑前:开始我们的探索之旅吧!
关于 Sed 的一点点理论知识首先我们看一下 sed 的运行模式要准确理解 Sed 命令,你必须先了解工具的运行模式。
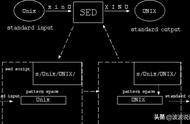
当处理数据时,Sed 从输入源一次读入一行,并将它保存到所谓的 模式空间(pattern space)中。所有 Sed 的变换都发生在模式空间。变换都是由命令行上或外部 Sed 脚本文件提供的单字母命令来描述的。大多数 Sed 命令都可以由一个地址或一个地址范围作为前导来限制它们的作用范围。
默认情况下,Sed 在结束每个处理循环后输出模式空间中的内容,也就是说,输出发生在输入的下一个行覆盖模式空间之前。我们可以将这种运行模式总结如下:
- 尝试将下一个行读入到模式空间中
- 如果读取成功:
- 按脚本中的顺序将所有命令应用到与那个地址匹配的当前输入行上
- 如果 sed 没有以静默模式(-n)运行,那么将输出模式空间中的所有内容(可能会是修改过的)。
- 重新回到 1。
因此,在每个行被处理完毕之后,模式空间中的内容将被丢弃,它并不适合长时间保存内容。基于这种目的,Sed 有第二个缓冲区: 保持空间(hold space)。除非你显式地要求它将数据置入到保持空间、或从保持空间中取得数据,否则 Sed 从不清除保持空间的内容。在我们后面学习到 exchange、get、hold 命令时将深入研究它。
Sed 的抽象机制你将在许多的 Sed 教程中都会看到上面解释的模式。的确,这是充分正确理解大多数基本 Sed 程序所必需的。但是当你深入研究更多的高级命令时,你将会发现,仅这些知识还是不够的。因此,我们现在尝试去了解更深入的一些知识。
的确,Sed 可以被视为是 抽象机制 的实现,它的 状态 由三个 缓冲区 、两个 寄存器 和两个 标志 来定义的:
- 三个缓冲区用于去保存任意长度的文本。是的,是三个!在前面的基本运行模式中我们谈到了两个:模式空间和保持空间,但是 Sed 还有第三个缓冲区: 追加队列(append queue)。从 Sed 脚本的角度来看,它是一个只写缓冲区,Sed 将在它运行时的预定义阶段来自动刷新它(一般是在从输入源读入一个新行之前,或仅在它退出运行之前)。
- Sed 也维护两个寄存器: 行计数器(line counter)(LC)用于保存从输入源读取的行数,而 程序计数器(program counter)(PC)总是用来保存下一个将要运行的命令的索引(就是脚本中的位置),Sed 将它作为它的主循环的一部分来自动增加 PC。但在使用特定的命令时,脚本也可以直接修改 PC 去跳过或重复执行程序的一部分。这就像使用 Sed 实现的一个循环或条件语句。更多内容将在下面的专用分支一节中描述。
- 最后,两个标志可以修改某些 Sed 命令的行为: 自动输出(auto-print)(AP)标志和<ruby替换 substitution(SF)标志。当自动输出标志 AP 被设置时,Sed 将在模式空间的内容被覆盖前自动输出(尤其是,包括但不限于,在从输入源读入一个新行之前)。当自动输出标志被清除时(即:没有设置),Sed 在脚本中没有显式命令的情况下,将不会输出模式空间中的内容。你可以通过在“静默模式”(使用命令行选项 -n 或者在第一行或脚本中使用特殊注释 #n)运行 Sed 命令来清除自动输出标志。当它的地址和查找模式与模式空间中的内容都匹配时,替换标志 SF 将被替换命令(s 命令)设置。替换标志在每个新的循环开始时、或当从输入源读入一个新行时、或获得条件分支之后将被清除。我们将在分支一节中详细研究这一话题。
另外,Sed 维护一个进入到它的地址范围(关于地址范围的更多知识将在地址范围一节详细描述)的命令列表,以及用于读取和写入数据的两个文件句柄(你将在读取和写入命令的描述中获得更多有关文件句柄的内容)。
一个更精确的 Sed 运行模式一图胜千言,所以我画了一个流程图去描述 Sed 的运行模式。我将两个东西放在了旁边,像处理多个输入文件或错误处理,但是我认为这足够你去理解任何 Sed 程序的行为了,并且可以避免你在编写你自己的 Sed 脚本时浪费在摸索上的时间。

The Sed execution model
你可能已经注意到,在上面的流程图上我并没有描述特定的命令动作。对于命令,我们将逐个详细讲解。因此,不用着急,我们马上开始!
打印命令打印命令(p)是用于输出在它运行那一刻模式空间中的内容。它并不会以任何方式改变 Sed 抽象机制中的状态。

The Sed `print` command
示例:
sed -e 'p' inputfile
上面的命令将输出输入文件中每一行的内容……两次,因为你一旦显式地要求使用 p 命令时,将会在每个处理循环结束时再隐式地输出一次(因为在这里我们不是在“静默模式”中运行 Sed)。
如果我们不想每个行看到两次,我们可以用两种方式去解决它:
sed -n -e 'p' inputfile # 在静默模式中显式输出
sed -e '' inputfile # 空的“什么都不做的”程序,隐式输出
注意:-e 选项是引入一个 Sed 命令。它被用于区分命令和文件名。由于一个 Sed 表达式必须包含至少一个命令,所以对于第一个命令,-e 标志不是必需的。但是,由于我个人使用习惯问题,为了与在这里的大多数的一个命令行上给出多个 Sed 表达式的更复杂的案例保持一致性,我添加了它。你自己去判断这是一个好习惯还是坏习惯,并且在本文的后面部分还将延用这一习惯。
地址显而易见,print 命令本身并没有太多的用处。但是,如果你在它之前添加一个地址,这样它就只输出输入文件的一些行,这样它就突然变得能够从一个输入文件中过滤一些不希望的行。那么 Sed 的地址又是什么呢?它是如何来辨别输入文件的“行”呢?
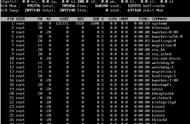
行号Sed 的地址既可以是一个行号($ 表示“最后一行”)也可以是一个正则表达式。在使用行号时,你需要记住 Sed 中的行数是从 1 开始的 —— 并且需要注意的是,它不是从 0 行开始的。
sed -n -e '1p' inputfile # 仅输出文件的第一行
sed -n -e '5p' inputfile # 仅输出第 5 行
sed -n -e '$p' inputfile # 输出文件的最后一行
sed -n -e '0p' inputfile # 结果将是报错,因为 0 不是有效的行号
根据 POSIX 规范 ,如果你指定了几个输出文件,那么它的行号是累加的。换句话说,当 Sed 打开一个新输入文件时,它的行计数器是不会被重置的。因此,以下的两个命令所做的事情是一样的。仅输出一行文本:
sed -n -e '1p' inputfile1 inputfile2 inputfile3
cat inputfile1 inputfile2 inputfile3 | sed -n -e '1p'
实际上,确实在 POSIX 中规定了多个文件是如何处理的:
如果指定了多个文件,将按指定的文件命名顺序进行读取并被串联编辑。
但是,一些 Sed 的实现提供了命令行选项去改变这种行为,比如, GNU Sed 的 -s 标志(在使用 GNU Sed -i 标志时,它也被隐式地应用):
sed -sn -e '1p' inputfile1 inputfile2 inputfile3
如果你的 Sed 实现支持这种非标准选项,那么关于它的具体细节请查看 man 手册页。
正则表达式我前面说过,Sed 地址既可以是行号也可以是正则表达式。那么正则表达式是什么呢?
正如它的名字,一个 正则表达式 是描述一个字符串集合的方法。如果一个指定的字符串符合一个正则表达式所描述的集合,那么我们就认为这个字符串与正则表达式匹配。
正则表达式可以包含必须完全匹配的文本字符。例如,所有的字母和数字,以及大部分可以打印的字符。但是,一些符号有特定意义:
- 它们相当于锚,像 ^ 和 $ 它们分别表示一个行的开始和结束;
- 能够做为整个字符集的占位符的其它符号(比如圆点 . 可以匹配任意单个字符,或者方括号 [] 用于定义一个自定义的字符集);
- 另外的是表示重复出现的数量(像 克莱尼星号(*) 表示前面的模式出现 0、1 或多次);
这篇文章的目的不是给大家讲正则表达式。因此,我只粘几个示例。但是,你可以在网络上随便找到很多关于正则表达式的教程,正则表达式的功能非常强大,它可用于许多标准的 Unix 命令和编程语言中,并且是每个 Unix 用户应该掌握的技能。
下面是使用 Sed 地址的几个示例:
sed -n -e '/systemd/p' inputfile # 仅输出包含字符串“systemd”的行
sed -n -e '/nologin$/p' inputfile # 仅输出以“nologin”结尾的行
sed -n -e '/^bin/p' inputfile # 仅输出以“bin”开头的行
sed -n -e '/^$/p' inputfile # 仅输出空行(即:开始和结束之间什么都没有的行)
sed -n -e '/./p' inputfile # 仅输出包含字符的行(即:非空行)
sed -n -e '/^.$/p' inputfile # 仅输出只包含一个字符的行
sed -n -e '/admin.*false/p' inputfile # 仅输出包含字符串“admin”后面有字符串“false”的行(在它们之间有任意数量的任意字符)
sed -n -e '/1[0,3]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”或“3”的行
sed -n -e '/1[0-2]/p' inputfile # 仅输出包含一个“1”并且后面是一个“0”、“1”、“2”或“3”的行
sed -n -e '/1.*2/p' inputfile # 仅输出包含字符“1”后面是一个“2”(在它们之间有任意数量的字符)的行
sed -n -e '/1[0-9]*2/p' inputfile # 仅输出包含字符“1”后面跟着“0”、“1”、或更多数字,最后面是一个“2”的行
如果你想在正则表达式(包括正则表达式分隔符)中去除字符的特殊意义,你可以在它前面使用一个反斜杠:
# 输出所有包含字符串“/usr/sbin/nologin”的行
sed -ne '/\/usr\/sbin\/nologin/p' inputfile
并不限制你只能使用斜杠作为地址中正则表达式的分隔符。你可以通过在第一个分隔符前面加上反斜杠(\)的方式,来使用任何你认为适合你需要和偏好的其它字符作为正则表达式的分隔符。当你用地址与带文件路径的字符一起来匹配的时,是非常有用的:
扩展的正则表达式# 以下两个命令是完全相同的
sed -ne '/\/usr\/sbin\/nologin/p' inputfile
sed -ne '\=/usr/sbin/nologin=p' inputfile
默认情况下,Sed 的正则表达式引擎仅理解 POSIX 基本正则表达式 的语法。如果你需要用到 扩展正则表达式 ,你必须在 Sed 命令上添加 -E 标志。扩展正则表达式在基本正则表达式基础上增加了一组额外的特性,并且很多都是很重要的,它们所要求的反斜杠要少很多。我们来比较一下:
花括号量词sed -n -e '/\(www\)\|\(mail\)/p' inputfile
sed -En -e '/(www)|(mail)/p' inputfile
正则表达式之所以强大的一个原因是 范围量词 {,}。事实上,当你写一个不太精确匹配的正则表达式时,量词 * 就是一个非常完美的符号。但是,(用花括号量词)你可以显式在它边上添加一个下限和上限,这样就有了很好的灵活性。当量词范围的下限省略时,下限被假定为 0。当上限被省略时,上限被假定为无限大:
括号速记词解释{,}*前面的规则出现 0、1、或许多遍{,1}?前面的规则出现 0 或 1 遍{1,} 前面的规则出现 1 或许多遍{n,n}{n}前面的规则精确地出现 n 遍
花括号在基本正则表达式中也是可以使用的,但是它要求使用反斜杠。根据 POSIX 规范,在基本正则表达式中可以使用的量词仅有星号(*)和花括号(使用反斜杠,如 \{m,n\})。许多正则表达式引擎都扩展支持 \? 和 \ 。但是,为什么魔鬼如此有诱惑力呢?因为,如果你需要这些量词,使用扩展正则表达式将不但易于写而且可移植性更好。
为什么我要花点时间去讨论关于正则表达式的花括号量词,这是因为在 Sed 脚本中经常用这个特性去计数字符。
地址范围sed -En -e '/^.{35}$/p' inputfile # 输出精确包含 35 个字符的行
sed -En -e '/^.{0,35}$/p' inputfile # 输出包含 35 个字符或更少字符的行
sed -En -e '/^.{,35}$/p' inputfile # 输出包含 35 个字符或更少字符的行
sed -En -e '/^.{35,}$/p' inputfile # 输出包含 35 个字符或更多字符的行
sed -En -e '/.{35}/p' inputfile # 你自己指出它的输出内容(这是留给你的测试题)
到目前为止,我们使用的所有地址都是唯一地址。在我们使用一个唯一地址时,命令是应用在与那个地址匹配的行上。但是,Sed 也支持地址范围。Sed 命令可以应用到那个地址范围中从开始到结束的所有地址中的所有行上:
sed -n -e '1,5p' inputfile # 仅输出 1 到 5 行
sed -n -e '5,$p' inputfile # 从第 5 行输出到文件结尾
sed -n -e '/www/,/systemd/p' inputfile # 输出与正则表达式 /www/ 匹配的第一行到与接下来匹配正则表达式 /systemd/ 的行为止
(LCTT 译注:下面用的一个生成的列表例子,如下供参考:)
printf "%s\n" {a,b,c}{d,e,f} | cat -n
1 ad
2 ae
3 af
4 bd
5 be
6 bf
7 cd
8 ce
9 cf
如果在开始和结束地址上使用了同一个行号,那么范围就缩小为那个行。事实上,如果第二个地址的数字小于或等于地址范围中选定的第一个行的数字,那么仅有一个行被选定:
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,4p'
4 bd
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,3p'
4 bd
下面有点难了,但是在前面的段落中给出的规则也适用于起始地址是正则表达式的情况。在那种情况下,Sed 将对正则表达式匹配的第一个行的行号和给定的作为结束地址的显式的行号进行比较。再强调一次,如果结束行号小于或等于起始行号,那么这个范围将缩小为一行:
(LCTT 译注:此处作者陈述有误,Sed 会在处理以正则表达式表示的开始行时,并不会同时测试结束表达式:从匹配开始行的正则表达式开始,直到不匹配时,才会测试结束行的表达式——无论是否是正则表达式——并在结束的表达式测试不通过时停止,并循环此测试。)
# 这个 /b/,4 地址将匹配三个单行
# 因为每个匹配的行有一个行号 >= 4
#(LCTT 译注:结果正确,但是说明不正确。4、5、6 行都会因为匹配开始正则表达式而通过,第 7 行因为不匹配开始正则表达式,所以开始比较行数: 7 > 4,遂停止。)
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,4p'
4 bd
5 be
6 bf
# 你自己指出匹配的范围是多少
# 第二个例子:
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/d/,4p'
1 ad
2 ae
3 af
4 bd
7 cd
但是,当结束地址是一个正则表达式时,Sed 的行为将不一样。在那种情况下,地址范围的第一行将不会与结束地址进行检查,因此地址范围将至少包含两行(当然,如果输入数据不足的情况除外):
(LCTT 译注:如上译注,当满足开始的正则表达式时,并不会测试结束的表达式;仅当不满足开始的表达式时,才会测试结束表达式。)
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '/b/,/d/p'
4 bd
5 be
6 bf
7 cd
printf "%s\n" {a,b,c}{d,e,f} | cat -n | sed -ne '4,/d/p'
4 bd
5 be
6 bf
7 cd
(LCTT 译注:对地址范围的总结,当满足开始的条件时,从该行开始,并不测试该行是否满足结束的条件;从下一行开始测试结束条件,并在结束条件不满足时结束;然后对剩余的行,再从开始条件开始匹配,以此循环——也就是说,匹配结果可以是非连续的单/多行。大家可以调整上述命令行的条件以理解。)
补集在一个地址选择行后面添加一个感叹号(!)表示不匹配那个地址。例如:
交集sed -n -e '5!p' inputfile # 输出除了第 5 行外的所有行
sed -n -e '5,10!p' inputfile # 输出除了第 5 到 10 之间的所有行
sed -n -e '/sys/!p' inputfile # 输出除了包含字符串“sys”的所有行
(LCTT 译注:原文标题为“合集”,应为“交集”)
Sed 允许在一个块中使用花括号 {…} 组合命令。你可以利用这个特性去组合几个地址的交集。例如,我们来比较下面两个命令的输出:
sed -n -e '/usb/{
/daemon/p
}' inputfile
sed -n -e '/usb.*daemon/p' inputfile
通过在一个块中嵌套命令,我们将在任意顺序中选择包含字符串 “usb” 和 “daemon” 的行。而正则表达式 “usb.*daemon” 将仅匹配在字符串 “daemon” 前面包含 “usb” 字符串的行。
离题太长时间后,我们现在重新回去学习各种 Sed 命令。
退出命令退出命令(q)是指在当前的迭代循环处理结束之后停止 Sed。