作者:胡锦波
什么是声源定位(Sound Source Localization,SSL)技术?声源定位技术是指利用多个麦克风在环境不同位置点对声信号进行测量,由于声信号到达各麦克风的时间有不同程度的延迟,利用算法对测量到的声信号进行处理,由此获得声源点相对于麦克风的到达方向(包括方位角、俯仰角)和距离等。
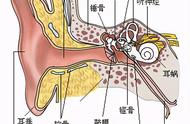
当谈及到声源定位,我们很容易联想到人耳定位,人的单耳和双耳都具有定位的能力。在单耳定位中,耳廓各部位会对入射声波进行反射,再进入耳道。由于与直达声波相位不同,两者在耳道出发生干涉,产生了特殊听觉效果,该效应称为耳廓效应,再配合人头转动因素,可以达到声源定位的目的。在双耳定位中,我们通过左耳和右耳接收到的信号会有时间差(Interaural Time Difference, ITD)和声级差(Interaural Level Difference, ILD),根据ITD和ILD对特定的声音进行定位,水平方位角的确定在数学上可以表述为一个二维声音方向估计问题,如下图1所示。ITD信息在中低频时的方位估计有更好的效果,而ILD信息在高频的方位估计有更好的效果。再加上耳廓效应、头部转动、优先效应等,我们会对角度、距离等信息有更进一步、更准确的认知。

图1 人头二维声源定位模型,图片来自文献[2]
一、引言我国古代关于声源定位的应用最早可以追溯到战国时期的墨家,《墨子》书中记载了“地听”和“瓷听”两种战争侦听方法。《备穴》篇中 “令陶者为罂,容四十斗以上,固顺之以薄革,置井中,使聪耳者伏罂而听之,审知穴之所在,凿穴迎之。”其大意是派人将瓦岗放置井中,在坛口中静听传自地下的声音,确切地弄清楚敌方隧道的方位,以抵御敌人挖隧道攻城的方法。
在第一次世界大战期间,科学家们发明了许多声学防御装置,期间最复杂的声音定位之一还属佩兰遥测仪 (Télésitemètre Perrin),它以法国物理学家Jean Baptiste Perrin的名字命名,如下图2所示。Perrin设计了一个用于跟踪飞机噪音(如发动机声、螺旋桨声、摩擦振动声、排气声)的接收装置,该接收装置将数十个小喇叭聚集在六边形蜂窝状巢穴中,这些 “喇叭” 通过一套管子连接到中央喇叭,两名监听员分别通过额外长度的管子进行双耳收听,通过手中方向盘对该装置转向以接收指定方向上的声音,如果设备朝向声源的方向,该接收器接收到的声音会同时到达,人们听到的两个传声器的声音会相互加强。

图2 Perrin遥测仪早期模型图片,来源不明
如今虽然有了更复杂的定位技术,但相位增强原理依然是现代声源定位系统的基础。为了改进需要机械地旋转设备来搜索相位增强方向的方法,人们对在固定位置的传声器上所测量的声音通过使用信号处理算法,以重新创造旋转的效果,从而避免了阵列的物理移动。
声源定位可以被用于船舶和车辆的检测、机器中(如发动机、汽车、飞机)主要噪声源的定位、通信设备或语音识别处理中的目标选择和干扰抑制,以及机械系统的状态监测。此外,由于能够估计声源强度和声场信息,声源定位方法已被广泛应用于音频设备和影院系统的声学设计、振动的非接触式测量,以及与其他用户间的虚拟现实音频系统。随着机器学习、云计算和片上电子技术的发展,声源定位技术将会有更加广阔的应用前景。
二、声源定位技术声源定位技术主要有以下两部分组成:
- 到达方向 (Direction-of-arrival, DOA) 估计,其中包括方位角与俯仰角。
- 距离估计。
接下来将讲述声源定位的端到端的模型、方法以及评价指标。

图3 声源定位通常使用的是球坐标系,坐标信息包括距离、方位角、俯仰角。图片来源于文献[3]
1. 端到端的模型声源定位端到端的模型如图4所展示的,对采集到的声音信号进行特征提取,然后使用声音定位方法来获得输出,而该映射方法很大程度依赖于声学传播模型。
传播模型(Propagation Model)。声源定位的声学传播模型比较常见的是自由场模型和远场模型。在自由场中,声音只通过一条直达的路径到达麦克风,这也意味着声源与麦克风之间没有阻挡物,没有声音的反射(没有室内的混响),例如空旷的室外或者消音环境室中。在远场中,麦克风间的距离和声源到麦克风阵列的距离之间的关系,使得声波可以被认为是平面波。

图4 声源定位端到端的模型,图片来源于文献[4]
特征(Feature)。在使用的声学定位方法中,使用了以下声学特征:到达时间差(Time difference of arrival, TDOA),麦克风间的能量差(Inter-microphone intensity difference, IID),频谱缺口(Spectral notches),MUSIC伪频谱(Pseudo-spectrum),以及波束形成可控响应(Beamforming steered-response)等。
映射方法(Mapping procedures)。声源定位中的映射方法是指将阵列信号中的特征映射为其位置信息。具体的技术方法将在下一小节讲述。
2. 实现方法(1)到达方向估计基于相对时延估计的方法。由于阵列的几何结构,各个阵列接收到的信号都有不同程度的延时,而基于相对时延估计的方法通过互相关、广义互相关(Generalized Cross-Correlation, GCC)或相位差等来估计各个阵列信号之间的时延差,再结合阵列的几何结构来估算声源的方位角信息。
基于波束形成的方法。该算法通常对阵列的各阵元使用所有角度补偿相位,以实现对目标区域的扫描,然后对各信号进行加权求和,将波束输出功率最大的方向作为目标声源的方向。常见的基于波束形成的声源方位角估计算法有延迟相加(Delay and Sum, DS)算法,最小方差无失真响应(Minimum Variance Distortionless Response, MVDR)算法,可控响应功率相位变换法(Steered Response Power-Phase Transform, SRP-PHAT)等。
基于信号子空间的方法。这类算法一般可以分为相干子空间方法和非相干子空间方法,在非相干子空间算法中,最经典的算法为多信号分类(Multiple Signal Classification, MUSIC)算法,其思想是将信号的协方差进行特征提取,利用特征向量构建信号子空间和噪声子空间,再将噪声子空间构建高分辨率空间谱。由于声源信号是宽带信号,可以对声源信号使用傅立叶变换分解成多个窄带信号,再对每个窄带利用MUSIC算法定位,将各窄带估计得结果加权组合得宽带方位估计。而相干子空间方法是将窄带信号汇聚到某一参考频率,从而采用窄带子空间处理方法进行方位估计。
基于模态域的方法。上述方法皆是阵元域的处理方法,而模态域的一大特性是其波束和导向矢量的频率无关,依据此可以设计出具有低频指向型的波束形成器,也可以降低阵元域波束扫描的频点数。模态域的处理方法与阵元域相比,其波束形成多出一步模态展开的操作,模态展开可通过傅立叶变换实现,展开后的每阶模态都有与之对应的空间特征波束,对应于特定的波束响应,可以看作是组合成期望波束响应的一组基。理论上来讲,只要模态展开的阶数足够高,理论是可以组合逼近成任意的波束。模态域的方法目前应用在球型阵列和环型阵列上有比较好的结果。
基于机器学习(或深度学习)的方法。与传统基于模型的方法相比,基于机器学习的方法是数据驱动的,甚至无需定义传播模型。基于机器学习的方法将声源定位看作是一个多分类或者线性回归问题,利用其非常强的非线形拟合能力,直接将多通道数据特征映射成定位结果。基于机器学习的方法主要也发展成了两种方向,即基于网格的方法和无网格的方法,这两种方法在定位精度和估计声源个数上各有优势。
(2)距离估计与DOA估计相比,声源距离的估计研究起步较晚。在得到DOA估计结果后,声源被定位在了由传声器和捕获信号之间的双曲线内,若采用多个传声器阵列对源信号进行DOA估计,则可通过每个传声器阵列的双曲线交点对声源进行定位。然而,该方法并不适用于远距离测距,许多研究也停留在室内的短距离声源测距上。
在室内条件下,当声源距离发生变化时,来自反射声的能量(如室内混响漫射声场)可以假定是保持不变,而来自直达声的能量会发生变化。这两种能量的比值被称为直达混响比(Direct-to-Reverberant ratio, DRR),该比值与声源距离的估计密切相关。理论上,信号的DRR可以通过声源到达传声器的房间冲激响应函数(Room Impulse Responses, RIRs)直接计算出。但声源距离的估计受多方因素的影响(如RIRs未知,近场与远场模型不匹配,混响能量会因距离的改变而改变等),这些方法并不成熟,无法得到很好的应用。
3. 评价指标针对DOA估计和距离估计的方法,需要依靠一些指标来衡量声源定位的性能,常见的评价指标如下:
平均误差(Average error)。它衡量的是估计的误差,通常将估计值与真实值进行比较,将这些值的平均差异表现出来。具体实现的方法包括绝对误差、均方误差、均方根误差和最大误差等。
准确率(Accuracy)。这个指标通常用于DOA估计,我们假定如果估计值在真实值一定的误差范围内,则认定该估计是正确的,否之,认定为错误。它衡量了多少比例的检测是正确的。
查准率(Precision)、查准率(Recall)和F1分数(F1-score)。这些指标在机器学习分类任务中比较常见的。针对估计一个声源的位置,如果估计正确,则称为真正例(True positive);如果估计错误,则称为假反例(False negative)。假设该位置没有声源,如果估计的结果也是没有,则称为真反例(True negative);如果估计的结果是有声源,则称为假正例(False positive)。查全率衡量所检测正确的声源位置个数占所有声源的比例;查准率衡量所估计到的声源位置中,有多少位置估计是正确的比例。一般来说,查准率和查全率呈负相关关系,而F1分数为这两个指标的调和平均,提供它们之间的平衡。
声源的数量(Number of sources)。该指标衡量所能估计到声源的数量,而不在乎声源的具体位置。
还有一些其他的性能指标,如将某声源定位方法用在语音识别、声源分离、语音拾取任务的预处理,上述任务依赖于声源定位的效果,通过这些任务的性能表现来间接评价声源定位的性能。
三、应用前景1. 故障诊断机械系统(如风力涡轮机和车辆的各种机械子系统)的在线状态监测和故障诊断,是声源定位的一个重要应用场景。一个可靠的在线诊断系统,需要在持续不断工作的机器上,从每个可能出现故障的部件中获得“干净”的数据。通常直接将传感器应用到每个部件上很困难,因此可以使用传声器在距离机械部件一定距离处获得声学数据,然后使用声源定位技术,作为虚拟传感工具来测量振动声学信息。此外,声学测量通常比光学测量等替代方法更节省成本。例如,在自动驾驶汽车领域,人们希望提升各种机械系统的故障诊断性能,从而确保驾驶的安全性与舒适性。
下图是一个典型的用于声源定位的传声器阵列,该阵列由36个传声器组成,用于识别柴油机的噪声源位置。

图5 照片由Tongyang Shi提供
2. 远场语音拾取在复杂的声学环境中,噪声、混响和非目标语音的干扰会显著影响拾取到的目标语音信号的质量和可懂度,进而影响后续的语音识别性能。作为远场语音拾取的前端处理——声源定位,它增强或保留目标源方向内的信号,抑制其他方向的信号,对说话人进行跟踪和后续的语音定向拾取。声源定位用于指导各类阵列算法,使其更适用于当前环境,其性能的优劣能直接影响后续算法(如声源分离、噪声抑制等)在实际声学环境中的鲁棒性,
四、现有方法所面临的挑战1. 对实时性与精度的要求实时性与精度是很多技术应用中都共有的问题,很多时候我们需要在实时性和精度方面权衡。由于人们对声源定位实时性与精度的需求不断提高,其性能也在持续改进中,改进的方式也依赖使用的场景、测试条件限制等。目前许多研究方法可以提供高精度的结果,但由于对三维空间(方位角、俯仰角和距离)的搜索,其时间复杂度太大,无法保证对实时性的需求,也就是说我们无法保证对声源目标实时地提供高精度(误差角度<1度,距离误差<1厘米)的三维坐标。
2. 平稳信号的假设大多数声学定位方法是在平稳假设下进行的,这意味声场特性不会随着时间而改变。这种假定使得定位技术无法应用于瞬时声源(如爆炸)或移动声源。在考虑移动声源(如高铁)的定位时,该运动已知时的可视化比运动未知时要容易得多。当声源轨迹给定时,有以下几种选择:
(1) 去除固定阵列测量信号的多普勒效应;
(2) 在全息技术或波束形成模型中加入移动声源的声场表达式;
(3) 如果阵列与信号源有相同的运动时,虚拟构建由阵列测量到的信号。
然而,在没有额外运动捕获工具的情况下,对具有未知运动的声源进行定位仍是一个开放的问题,几乎没有实用的解决方案。
3. 硬件的限制为了确保良好的定位性能,许多方法甚至需要上百个传声器,在硬件的成本花销限制了这些技术的应用。此外,传声器阵列的安装、布线会导致无法忽略的声学散射,降低传声器的测量精度,从而损害声源定位的性能。任何物体,即使是放置在声场中相对较小的传声器,都会扰乱被测量的声场,这对声场可视化的准确性会产生不利影响。这个问题会因为固定传声器位置的支撑结构和连接布线系统的电缆的存在而变得更糟。
目前,MEMS传声器正被广泛应用,这些传声器体积小、功率适中、消除了对外部电源的需求,可以尽量减少散射效应。若将数据采集系统以无线方式进行,便会完全消除对电缆的需求。这些都是有效的措施,但还在发展中的更好方法是——完全取消传声器测量,并采用完全非侵入式的测量程序代替。
五、未来展望在过去几十年里,声源定位领域有了巨大的发展,很多问题都得到了解决。例如,在半个世纪以前,研究人员认为声源定位在噪声和混响的条件下,其鲁棒性非常差,认为这个问题几乎不可能解决,但现在很多针对声源定位方法也正是基于噪声和混响条件下的研究,性能也得到很好的改善。
目前的方法也存在如上一节所述的局限性,而且在声源定位中,仅依靠音频信号对距离进行估计的研究方法效果较差,但如今的趋势表明,这些研究问题正不断得到解决。
参考文献[1] Yangfan Liu, J. Stuart Bolton, and Patricia Davies. Acoustic Source Localization Techniques and Their Applications[J]. The Bridge, 2021, 51(2): 34-40.
[2] Pan Z, Zhang M, Wu J, et al. Multi-Tone Phase Coding of Interaural Time Difference for Sound Source Localization with Spiking Neural Networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 2656 – 2670.
[3] Risoud M, Hanson J N, Gauvrit F, et al. Sound source localization[J]. European annals of otorhinolaryngology, head and neck diseases, 2018, 135(4): 259-264.
[4] Rascon C, Meza I. Localization of sound sources in robotics: A review[J]. Robotics and Autonomous Systems, 2017, 96: 184-210.
[5] 王子腾. 结合深度学习的麦克风阵列远场拾音算法研究[D]. 北京: 中国科学院声学研究所, 2019.
[6] 张国昌. 鲁棒声源定位方法研究[D]. 北京: 中国科学院声学研究所, 2019.
[7] 丁建策. 室内监督式双耳声源定位研究[D]. 北京: 中国科学院声学研究所, 2019.
[8] 何万龄, 刘凤英. 人耳对声源方位的判定[J]. 生物学通报, 1991(03): 13-14.
[9] 冯建辉, 王明红, 祝家清. 中国古代声学思想及其应用[J]. 高等函授学报(自然科学版), 1996(04): 12-15.
[10] https://mp.weixin.qq.com/s/SFeKnVwqwBDYrwZXH8khOA
[11] Lee S Y, Chang J, Lee S. Deep learning-based method for multiple sound source localization with high resolution and accuracy[J]. Mechanical Systems and Signal Processing, 2021, 161: 107959.
[12] 周志华. 机器学习[M]. 清华大学出版社, 2016: 28-32.
,