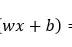数据集
假设该数据集分布如下:

数据集分布
那么我们的目标就是找到这样一条直线可以将上述数据线性可分,即将圆形划为一类(假设为反例,y=0),将五角星划为一类(假设为正例,y=1)。这样的直线我们称为决策边界,Logistic回归模型的任务就是要学习出决策边界。上述问题的决策边界可以表示为w1x1 w2x2 b=0,在该决策边界上方的样本为一个类别(正例),在该决策边界下方的样本为另一个类别(反例)。
我们令w=(w1, w2)^T,x=(x1, x2)^T,那么上述决策边界就可以写成w^Tx b=0。实现上述分类最理想的函数是单位阶跃函数。

单位阶跃函数
但是这个阶跃函数是不可微的,因此我们使用形如sigmoid函数的对数几率函数来代替它,我们将y视为x为正例的概率,则1-y就是x为反例的概率,两者的比值(该事件发生与不发生的概率比值)称为几率,最终改写公式如下:

对数几率函数改写公式
也就是说,输出y的对数几率是由输入x的线性函数表示的模型,这就是Logistic回归模型。可以看到,当w^Tx b的值越接近正无穷,x为正例(y=1)的概率就越接近1。
至此我们可以得出结论,Logistic回归模型的思路就是拟合决策边界(多项式,而不仅仅局限于线性),再建立这个边界与分类的概率联系,从而得到分类情况下的概率。
至此,我们得出结论:Logistic回归实际上是使用线性回归模型的预测值逼近分类任务真实标记的对数几率。
损失函数有了如上模型的假设与训练数据后,我们就可以把模型中的参数求出来。在统计学中,我们常常使用极大似然估计法来估计模型参数,即找到一组参数,使在这组参数下,数据的似然度(概率)最大。以上述的二分类问题为例,假设P(y=1|x)=p(x),则P(y=0|x)=1-p(x)。那么似然函数如下: