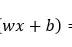似然函数
我们对上述等式两边同时取对数,得到对数似然函数:

对数似然函数
机器学习中通常使用损失函数来衡量模型预测错误的程度,我们令该模型的损失函数为整个数据集上的平均对数似然损失,那么Logistic回归模型的损失函数为:

损失函数
可以看到,在逻辑回归模型中,最大化似然函数和最小化损失函数实际上是等价的。
我们平常所说的最小化损失函数就是为了优化模型,优化的主要目标是找到一个方向,使得参数朝这个方向移动之后损失函数的值能够减小。我们使用随机梯度下降法来求解,具体来讲,就是通过J(w)对w的一阶导数来寻找梯度下降方向,并且以迭代的方式来更新参数。J(w)对w的一阶导数求解过程如下:

求导过程
得到一阶导后就可以使用它和超参数学习率α来更新参数w(k 1)=w(k)-α*一阶导。其中,k为迭代次数,我们可以设定最大迭代次数来停止迭代,也可以设置一个阈值,根据每次迭代后比较||J(w(k 1)) - J(w(k))||是否小于这个阈值来判断是否停止迭代。
,