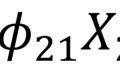本文的目的是为主成分分析(PCA)提供一个完整且简单的解释,特别是其运作方式,以增进大家对该分析法的理解并加以利用,而不必具有强大的数学背景。
PCA实际上是网上广泛提及的一种方法,很多文章都有涉及。但是,只有极少数文章能直接切入主题,并在不过多钻研技术细节的前提下解释PCA的工作原理以及“为什么”。这就是这篇文章的目的:以更简单的方式解释主成分分析法。
在开始解释之前,本文提供了PCA在每一步骤的运作原理的逻辑解释,简化了其背后的数学概念,如标准化,协方差,特征向量和特征值,而暂未关注如何运算的问题。

什么是PCA?
PCA是一种常用于减少大数据集维数的降维方法,把大变量集转换为仍包含大变量集中大部分信息的较小变量集。
减少数据集的变量数量,自然是以牺牲精度为代价的,降维的好处是以略低的精度换取简便。因为较小的数据集更易于探索和可视化,并且使机器学习算法更容易和更快地分析数据,而不需处理无关变量。
总而言之,PCA的概念很简单——减少数据集的变量数量,同时保留尽可能多的信息。
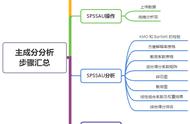
逐步解释
第1步:标准化
这一步的目的是把输入数据集变量的范围标准化,以使它们中的每一个均可大致成比例地分析。
更具体地说,在使用PCA之前必须标准化数据的原因是PCA对初始变量的方差非常敏感。也就是说,如果初始变量的范围之间存在较大差异,那么范围较大的变量将占据范围较小的变量(例如,范围介于0和100之间的变量将占据0到1之间的变量),这将导致主成分的偏差。因此,将数据转换为可比较的比例可避免此问题。
在数学上,这一步可以通过减去平均值,再除以每个变量值的标准偏差来完成。