图3:金融借贷服务流程再设计-用户画像创建流程
再者,从机器学习角度上来说,聚类分析是一种无监督学习unsupervised learning,根据不同的数据选取策略和不同的聚类算法,系统会给出不同的分类模型。
至于哪个模型是贴合研究实际的“最优解”,需要研究者自行决定。这意味着在做用户分类时,我们所依赖的工具需要在研究者所提供的浩如烟海的数据当中根据数据的分布形态,逐渐探索出数据的分类形态,因此最终数据分类的结果质量对研究者对数据的理解、把握和解读有着更高的要求。
这要求研究者在使用数据进行聚类之前,应当对数据的业务内涵具有相当程度的把握和敏感性。
02 聚类分析用于用户分类的操作流程1)样本数据选择
根据前期的定性研究和已经生成的假设,选择能够用来描述和定义用户的数据维度。在本案例中,通过定性访谈、内部访谈等研究,研究者已经得知,不同用户在借贷周期、借贷金额、还款履约行为、犹豫周期上存在着很大差别,因此,研究者可以有目的地选择可能有用的数据。可以列出所需维度的数据清单,向数据负责人获取。
在选择数据时,也可以查阅相关文献,如行业竞品常用的数据/参数模型,建立对研究所需数据标签的感知。图4为本案例在选择样本数据时参考的某银行产品用户标签体系。

图4:某银行金融产品用户标签体系
2)样本数据清洗
这一步骤的目的在于去除缺省值、异常值、不合理值、非研究范畴值,研究者可以根据项目的实际需求,去除可能成为干扰项的数据。如:对收入进行标准化处理,剔除3个标准差外的异常值,去除超越研究范畴(如60周岁以上)的样本。
注意保存清洗逻辑并在团队成员间共享,以便随时恢复被误删除的数据。
3)数据编码及标准化
涉及到数据类型的转换和数据可读性的调整,由于聚类分析需要用到一定规模的连续变量和分类变量,对于一些界定模糊的变量,需要团队成员商议后给予其明确的数据类型定义,并给出相应的定义值。此外,注意保存这些编码逻辑,业务数据往往夹杂着诸多术语和缩写,研究员需将其转为易读的符号并加以记忆。
如图5,本案例中,申请类型、进件渠道、还款方式属于分类变量,B卡评分描述了用户的信用程度,则可以定义为等级变量或连续变量。

图5:金融借贷服务流程再设计-原始数据编码逻辑片段
此外,为了顺利进行聚类分析算法的运转,需将不一致的数据单位调整为一致的、标准的计量单位,如:将“利率”统一转化为“月利率”或“年利率”。
4)变量处理与提取特征
这一步骤目的在于使冗余的数据得到凝缩和降维。
原始变量可能会有几百上千的维度,但最终用于聚类分析的变量需要能够很好地描摹用户行为,有时研究者需要对数据进行一些简单加工,得到一些更为关键的变量。如:研究者可以用最终办理进件时间减去首次用户问询时间,得出中间的差值,该变量(犹豫时长)可以用来形容用户在金融借贷产品中的消费风格。
此外,聚类分析算法要求变量与变量之间具有较强的独立性,因此,需要研究者尽可能地整合相关性较大的变量,更严谨的做法则可以借助关联规则分析发现并排除高度相关的特征,或通过主成分分析进行降维。
5)选择聚类分析算法
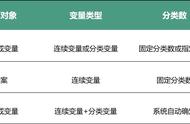
在 SPSS统计分析软件中,常用的聚类分析算法包含二阶聚类 twostep、K-均值聚类 K-means、系统/层次聚类 Hierarchical。不同聚类分析的算法逻辑不同(本文不再赘述)所需要用到的变量类型也有所不同,适用的样本群体也略有差异。研究者可根据项目的实际需要来选择相应的算法。如图6:

图6:根据项目实际需要选择相应算法
本案例中,研究者选择了二阶聚类算法,这种算法无需人为设定最终分类个数,有助于实现对人群样本聚类的探索。
6)选择变量进行聚类——检验模型效果
这一步骤是漫长的探索过程,需要研究者不断尝试,选择适量的变量进行聚类分析运算,并检视模型质量和前期研究的适配度。研究者往往需要尝试几十、几百次的更换变量、修改参数,才能得到一个聚类质量较高、模型解释力强的分类模型。
本案例中,研究者选择了B卡评分、还款方式、累计逾期次数、利率、使用率(用款金额占授信额度的占比)、收入、月利息共7个变量,包含连续变量和分类变量,最终得到图7的聚类模型。研究者可以在“模型摘要图”打开模型浏览器,看到聚类质量、聚类大小等图表形式结果(图8)。