算法可以说是AI技术的核心,想入门AI的同学,了解一些算法知识是很有必要的。这篇文章里,作者就介绍并梳理分析了AI无监督学习中的聚类算法,一起来看看其工作原理和应用场景吧。

各位看官:
欢迎一起探索AI的世界。就在开年的2月21日,国务院国资委召开中央企业人工智能专题推进会扎实推动AI赋能产业焕新,这一消息在国务院国有资产监督管理委员会官网上公布,国家队的重视也是全民拥抱AI的大好时机。
OpenAI和Sora掀起了一股全民科技热潮,又加之当前经济需要新的科技和新的需求来推动市场发展,原因很多,错综复杂。但无论是因为什么,拥抱AI都会成为当今互联网从业人员的不二选择。

现如今,大家都多多少少知道一些AI,特别是一些AI应用的名称,但论及AI的技术原理,并非人人皆知。当然,大部分人也不需要知道背后的原理,就像我们去餐厅吃饭时,会尽情品尝菜肴的美味但不一定需要知道每样食材的品种和产地。
那么,哪一类人群需要在拥抱AI的浪潮中还需习得AI的技术原理呢?
是原互联网行业要转型AI行业的一批人,或者刚毕业要进入AI行业的新手小白,这些人是市场上新诞生的一群AI从业人员,也正是这些人,将有更大的机会在AI行业创造出新的社会价值。
互联网科技人员是市场上最早一批接触AI的人,在OpenAI还未火遍全球之前,就已经有一批人在一些细分领域做着AI相关的工作,只不过那时候的AI市场还没那么大。
而且那时候,互联网领域无论是C端还是B端都存在着大量的市场机会,大量的市场需求未被满足,就算不涉及AI,无论是个人还是公司,都有着巨大的增长空间。
但是现在,一切都在改变,拥抱变化将是我们面对市场不确定性的主要节奏,原互联网从业人员,上至大厂下至小初创公司,都不能固守着原先互联网模式的一亩三分地,止步不前只会将自己圈禁待死。
所以说,无论是想转型AI,还是新手入门AI,都必须具备AI领域一定程度的专业能力。为了了解AI,我们可以去学习如何操作市面上的AI工具,把现今流行的文生文,文生图,文生视频都玩一个遍。
但重点是,我们在体验之余,也要静下心来想想,如果想在AI这条路上走出自己的核心竞争力,仅仅会操作AI工具是否足以支撑自己走得稳,走得远?
若想成为AI行业中有独特竞争力的一员,首要就是打好AI基本功。形成这个观点,不仅是基于我在互联网多年的从业经验,也是基于国内外大量公司和个人的成功案例。
也许功能或产品会被借鉴,人才会被挖走,但有些竞争力形成的护城河,就算公开于众,也是夺不走的,这就是真正的实力,背后也是因为有着扎实的基本功做支撑。
入门AI,无论从哪个角度切入,都要先克服畏难情绪,日拱一卒,一步一脚印地磨练AI基本功。我们从AI的专业知识开始,逐步构建自身的核心竞争力。
本章要说的主要内容就是AI无监督学习中的算法。算法是AI技术的核心。了解算法对于提高AI应用的性能和效率至关重要。
类似ChatGPT,背后的算法能够从数据中学习并生成新的内容,我们需要了解这些AI算法的工作原理和应用方式,以便更好地将它们融入自己的产品和业务中。
全文8000字左右,预计阅读时间15分钟,若是碎片时间不够,建议先收藏后看,便于找回。
照例,开篇提供本篇文章的目录大纲,方便大家在阅读前总揽全局,对内容框架有预先了解。

1. 算法是什么,能吃吗?
哈哈,开个小玩笑,算法当然不能吃了。算法是一系列定义明确的操作步骤,用于解决特定问题或完成特定任务。
我们常见的算法通常指的是计算机科学中的一个概念,它涉及到数据的处理、转换和计算,用于实现某个目标或解决某个问题。
也可以简单理解成,算法是通过数据来解决问题的一种工具。往小了说,像四则运算、定理公式都可以称之为算法。嗯,1 1=2,也是一种算法。所以,算法并没有我们以为的那么高深莫测。
在AI和机器学习领域,算法被设计用于从数据中学习、发现模式、做出预测或执行决策,而无需显式的编程。
算法可以是简单的,比如排序一组数字,也可以是复杂的,比如识别图像中的对象或理解自然语言文本。在AI领域,算法被用来处理人力所不及的领域,像“1 1=2”这类的问题,就犯不着用上算法啦。
算法概念很广,我们主要围绕机器学习中的算法展开讨论。在机器学习中,算法通常分为以下几类:
【监督学习算法】
监督学习算法通过使用已标记的训练数据(输入和相应的输出)来学习模型。通过建立一个从输入到输出的映射,让模型能够对新的未标记数据进行预测。
常见的监督学习算法包括线性回归、决策树、支持向量机等。
【无监督学习算法】
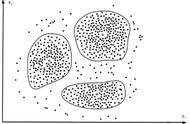
无监督学习算法则需要在没有明确标签的情况下从数据中学习结构和模式。这类算法主要用于聚类、降维和关联规则挖掘等任务。
比如,K均值聚类、主成分分析(PCA)和关联规则挖掘都是常见的无监督学习算法。
如果对无监督学习的基本概念还不太清楚的,推荐我上一篇写的《现在入门“AI无监督学习”还来得及(9000字干货)》,和本篇有相关联之处,一起看看有助于加深理解。
【半监督学习算法】
半监督学习算法通常会结合监督学习算法和无监督学习算法的优势,利用同时包含有标签和无标签数据的训练集进行模型训练。
这样的组合允许算法在一部分数据上学习有监督的模式,又从未标记的数据中学习无监督的结构。常见的半监督学习算法包括半监督支持向量机(SVM)、自训练(Self-training)和混合模型(Mixture Models)等。
【强化学习算法】
强化学习是一种通过与环境的交互来学习行为的方法,强化学习算法的核心思想是通过试错来学习。
在这种学习方式下,智能体尝试通过不同的行为来观察环境的反馈,选择在不同状态下采取动作,而后进行学习并优化,目的就是实现最大化预期的总奖励。
一些经典的强化学习算法包括Q-learning、Deep Q Network(DQN)、Policy Gradient等。