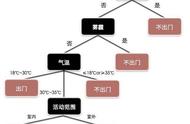
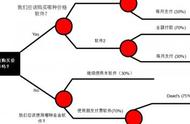
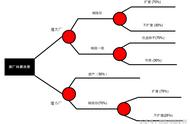
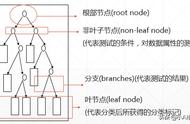
1984年多位统计学家出版了著作《Classification and Regression Trees》,介绍了二叉决策树的产生。ID3、C4.5和CART都采用贪心(即非回溯的)方法,其中决策树以自顶向下递归的分治方法构造。大多数决策树归纳算法都沿用自顶向下方法,从训练元组集和它们相关联的类标号开始构造决策树。随着数的构建,训练集递归地划分成较小的子集。
算法Generate_decision_tree。由数据分区D中的训练元祖产生决策树。
输入:
数据分区D,训练元祖和它们对应类标号的集合。
Attribute_list,候选属性的集合。
Attribute_selection_method,一个确定“最好地”划分数据元组为个体类的分裂准则的过程。这个准则由分裂属性(splitting_attribute)和分裂点或划分子集组成。
输出:一棵决策树
方法:
(1)创建一个节点N;
(2)If D中的元祖都在同一类C中then
(3) 返回N作为叶结点,以类C标记;
(4)If attribute_list为空then
(5) 返回N作为叶结点,标记D中的多数类; //多数表决
(6)使用Attribute_selection_method(D,attribute_list),找出“最好地”spitting_criterion;
(7)用splitting_criterion标记节点N;
(8)If splitting_attribute是离散值的,并且允许多路划分then //不限于二叉树
(9) attribute_list ←attribute_list-splitting_attribute; //删除分裂属性
(10)for splitting_criterion的每个输出j //划分元祖并对每个分区产生子树
(11)设Dj 是D中满足输出j的数据元组的集合;
(12)If Dj为空then
(13)加一个树叶到结点N,标记为D中的多数类;
(14)else加一个有Generate_decision_tree(Dj,attribute_list)返回的结点到N;
endfor
(15)返回N;
In 1984, many statisticians published the book "Classification and Regression Trees", which introduced the generation of binary decision trees. ID3, C4.5 and CART all adopt a greedy (that is, non-backtracking) method, in which the decision tree is constructed with a top-down recursive divide-and-conquer method. Most decision tree induction algorithms follow the top-down approach, starting with the training tuple set and their associated class labels to construct the decision tree. As the number is constructed, the training set is recursively divided into smaller subsets.
Algorithm Generate_decision_tree. The decision tree is generated from the training ancestor in the data partition D.
enter:
Data partition D, a collection of training ancestors and their corresponding class labels.
attribute_list, a collection of candidate attributes.
Attribute_selection_method, a process of determining the "best" division of data tuples into individual categories. This criterion is composed of splitting attributes (splitting_attribute) and splitting points or sub-sets.
Output: a decision tree
method:
(1) Create a node N;
(2) The ancestors of If D are all in the same class C then
(3) Return N as the leaf node, marked with class C;
(4) If attribute_list is empty then
(5) Return N as the leaf node and mark the majority class in D; //majority voting
(6) Use Attribute_selection_method(D,attribute_list) to find the "best" spitting_criterion;
(7) Mark node N with splitting_criterion;
(8) If splitting_attribute is a discrete value, and allows multiple partitions then // not limited to binary trees
(9) attribute_list ←attribute_list-splitting_attribute; //Delete splitting attribute
(10) Each output j of for splitting_criterion // divide the ancestor and generate a subtree for each partition
(11) Let Dj be the set of data tuples satisfying output j in D;
(12) If Dj is empty then
(13) Add a leaf to node N and mark it as the majority class in D;
(14) Else adds a node returned by Generate_decision_tree(Dj, attribute_list) to N;
endfor
(15) Return N;
参考资料:百度百科
翻译:Google翻译
本文由LearningYard学苑原创,文中部分图片和文字均来源于网络,如有侵权请联系删除!
,