小学课上我们就学过矩形的面积等于长乘以宽。
但活了几十年,你有没有想过:矩形面积为啥等于长乘以宽?
或者说先人们为何将矩形的面积定义为长乘以宽?
(继续之前,请先忘掉矩形面积等于长乘以宽这个“简单”的知识)。
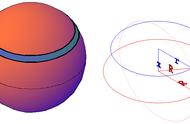
时光倒退几千年,小林是个好奇心极强的农夫,某天闲来无事,端着一杯茶盯着自家一块地,就像下面这形状:

小林突然想搞清楚这块地有多大。于是他用尺子量了量:

他发现这块地长边是 100 米,短边是 50 米。小林分别给这两个边起了个名字:长(长边)、宽(短边)。
因而现在可以说这块土地大小是长 100 宽 50。
但小林那该死的好奇心对这个结果并不满意:它想知道这么大的矩形所围出来的区域(阴影部分)到底是多大——它想用一个数字来表达这个区域。
小林现在还不知道这个长 100 宽 50 的矩形区域到底如何用数字表示——但到目前为止,这不重要,重要的是先给它起个名字。
名字叫什么都行,不过最好能直观,比如区域、面积——不妨就叫面积吧。
另外小林想求解的是通用矩形的面积(而不是长 100 宽 50 的”这个“矩形),所以他决定用一些符号来通用地表示矩形的长和宽。不妨用 l(或者别的什么符号都行)代表长,用 w 代表宽。

现在问题变成:求长 l 宽 w 的矩形的面积是多少?
答案是:不知道!
到目前为止,小林的脑袋里的数学知识只有数字(自然数)、加、减和乘——面对这个陌生的”面积“概念,他一筹莫展。
人类有个天生的”优点“:善于自欺欺人。
我们不知道矩形面积是多少对不对?但可以假装知道啊!
就像我们给矩形的长和宽符号化一样,我们也可以给面积一个符号。
给什么符号无所谓,X、Y、面、# 都行——不妨管它叫 S 吧(虽然后人总是从语言历史的角度来考证符号的含义,但实际上给它什么符号真的无所谓)。
现在小林好像多了一点知识:知道了长 l 宽 w 的矩形的面积是 S。
但实际上他又什么都不知道——其实不然,他凭经验感觉这个 S 和 l、w 有关系(有什么关系还不清楚)。
为了表示这个”重大“的发现(S、l、w 之间存在某种关系),**小林给出如下缩写:S(l,w)**。
(用其它任何缩写都行,比如 S[l,w]、l,w -> S 等等,我们之所以用 S(l,w) 纯属个人偏好。)
S(l,w) 和 S 这两种表达其实是一个意思,都是表示矩形的面积,只不过前者多了进一步的含义:矩形的面积和长 l、宽 w 多少存在某种关系。
接下来小林自然就会想:它们到底存在什么关系呢?
他低头思考了半天不得其解。
就在小林快放弃的时候,他的眼角余光瞟向那一亩三分地,小林想:既然它们存在关系,那我就试着改变长和宽,看看面积会发生什么变化?
首先,他把长 l 加倍:

小林发现,长加倍后,面积也明显加倍了,于是得到如下等式:
S(2l,w) = 2S(l,w)
有点意思!
接下来将长保持不变,宽加倍试试:

面积同样加倍了:
S(l,2w) = 2S(l,w)
小林觉得看到希望了!
于是他拿起树枝在地上画起来——小林发现,无论长、宽增加(或减少)多少倍,面积都跟着增加(或减少)一样的倍数。于是小林写下了如下式子:
S(#l,w) = #S(l,w)
S(l,#w) = #S(l,w)
表示任意数。上面的式子是说:我们可以将矩形的长拆分成两个任意数(#、l)的乘积,然后将其中一个数从括号里面拿出来。对于宽也是如此。接下来就要发挥人类的推理能力了。
S(l,w) 可以写成 S(l*1,w)。按照上面的式子,我们可以将 l 从括号里面拿出来得到:
S(l,w) = S(l1,w) = lS(1,w)
我们再对 w 做同样的处理,得到:
S(l,w) = S(l1,w) = lS(1,w) = lS(1,w1) = lwS(1,1)
也就是说:S(l,w) = lwS(1,1)。
至此小林得到结论:长 l 宽 w 的矩形的面积是 长 1 宽 1 的矩形的面积的 l*w 倍。
小林并没有得到一个绝对数,而是得到了一个相对于 长 1 宽 1 的长(正)方形的面积的倍数。
因为这个长 1 宽 1 的矩形面积总是固定的,所以我们并不需要关心它的面积绝对值到底是多少,我们可以把它人为地定义为 1,那么长 l 宽 w 的矩形的面积就是 l*w。
这个思想很重要:我们在现实世界中理所当然地认为是绝对值的(比如这里的面积),其实本质上是相对值。
比如 3 米到底是多长?它取决于 1 米有多长。
1 分钟有多久?它取决于 1 秒有多久。
这些作为度量参照的,我们称之为单位。
最底层的单位是人为定义的,而且在人类的不同历史时期可能有不同的定义。比如中国古代的 1 斤跟现代的 1 斤在重量上并不相等,但它并不妨碍两个时代人的日常使用。
怎么做的?在一般人看来,数学是人类最严谨的学科,就好像是神灵赐予人类的先验礼物。
数学是严谨不假,但数学的基础并不是先验的,而是源自人类生活的经验。
虽然数学中充斥着大量的公理、证明啥的,但数学最底层却是一些”简单“的公设(公理。比如平面几何学中的五大公设)。小学老师告诉我们:所谓公理,是不需要证明的(不证自明)。这个所谓的”不证自明“,说白了就是凭经验。
不但数学中最基本的公理凭经验,数学中的很多求证过程也是凭经验——虽然听起来不可思议。
我们回头看看矩形面积的推导过程:
一开始我们只是好奇心作怪,想知道如何用数来表示这么一块矩形区域(定义问题)。
我们发现自己不知道怎么求解它,没办法只能给它个代号(符号化)。
另外我们发现矩形有两个属性:长和宽(参数化)。
经验告诉我们,矩形面积跟矩形的长和宽存在某种关系(关联)。
于是我们根据经验试图去寻找它们之间到底存在哪些关系(找规律)。
经过穷举,我们得到了几个很有意思的等式。
再经过一番思考和观察,我们发现这几个等式可以泛化成一般等式(就是里面的具体数值可以变量化)。(关系泛化)
面对一般化的等式,我们利用已有知识(如 w = w * 1,即一个数乘以 1 等于它自身,这是根据乘法的定义得出的结论),最终推导出我们想要的东西(基于既有知识的逻辑推理)
在整个过程中,经验、观察、实验、符号化起到非常重要的作用。
关程序员何事?这里涉及到我们如何思考和解决问题。
当我们面临一个陌生的(而且看起来很难的)问题时,本能反映是摸不着头脑。
然后就开始抓瞎。
我们要做的是,在抓瞎之前冷静一下,眼睛看看远方,做几次深呼吸,然后再多想几次问题本身。
不要在还没搞清楚问题是什么之前就开始解决问题。
我们举个字符串编辑距离的例子。
问题:给定两个字符串 str1 和 str2,求 str1 至少需要经过多少次操作才能变成 str2。
你第一次遇到这个问题是什么感受呢?反正我是一脸懵逼,狗咬刺猬,无处下牙。
然后的感觉是:这个问题我好像没怎么弄明白?
所以要先分析问题本身。
什么叫”经过多少次操作“?
想要知道经过多少次操作,起码先要知道都有什么样的操作吧?
我们记得前面那位老农是面对着他的一亩三分地想问题——而我们现在面对的是两个抽象的(符号)str1 和 str2。
所以接下来要将抽象的问题具象化。
我们不妨写两个具体的字符串:
str1 = "abcd"
str2 = "acdb"
现在变成了具体的问题:怎样通过最少的操作将字符串"abcd"变成"acdb"?
这个问题其实分两部分:
- 怎样的操作?
- 最少的操作?
一个字符串想变成另一个字符串,它总要一个字符一个字符地处理吧(你不可能连看都不看某个字符一眼就能做出正确决定)。
所以”操作“这个概念就变成了”一个字符怎样变成另一个字符“的问题。
我们就看第一个字符:str1 中的 a 如何变成 str2 中的 a?
想都不用想,它俩相等,不用做任何操作——不做任何操作本身就是一种操作类型。
然后我们看看第二个字符:str1 中的 b 如何变成 str2 中的 c?
它俩不一样,所以必须做些行动才行。
一种方案是,将 b 替换成 c。
第二种方案是,直接将 b 删除掉,让它后面的字符来应对 c 这个字符。
第三种方案是,在 a 和 b 之间插入 c(将 b 挪到后面去)。
没有其他方案了。
至此我们搞明白了所谓”操作“到底是什么:啥也不做、替换、删除、插入,一共四种。
然后我们再把那个恐怖的修饰语”最少的“加上去——你会发现此时头又大了。
如果不限制”最少“,其实很好办,最无脑的做法就是先把 str1 中的字符全删掉,然后再一股脑把 str2 中的每个字符挨个插入即可,操作步数是 n m(两个字符串长度之和)。
这个最无脑的解法虽然无用,但它揭示了该问题的最大操作步数是 n m,所以如果你整出的解比它还大,那肯定不对了。
我们再回到上面的具体字符串:怎样通过最少的操作将字符串"abcd"变成"acdb"?
我们一个一个尝试。
其中一种方案是:第一个 a 保持不变,删掉第二个 b,最后在 d 后面插入 b,操作步数是 2。
然后我们又人肉尝试了其它方案,发现所有方案中最小的就是 2。
然而,问题好像并没有什么进展——我们仍然不知道如何求得最少步数(除了人肉)。
如果我们的思路一直停留在具象的具体问题上,便不太可能得到问题的解。
人类区别于其他动物的地方在于,人类能够将具象的事物(现象)提升成抽象的符号,进而形成思维模型(这也正是数学的奥秘,现在你应该能够理解数学家为啥那么喜欢玩符号了)。
将问题具象化有助于我们深刻理解问题本身,现在是时候让思维从具象回到抽象层面了。
我们先对字符串本身做抽象化表述。
字符串就是字符序列,它的本质就是集合(外加了个限制:顺序相关,即里面的字符有特定顺序)。
如何通过最少操作步数将长度为 n 的字符序列 {x,y,z⋯}n 转换成长度为 m 的字符序列 {x′,y′,z′⋯}m?
答案是:不知道!
那位农夫在求不出面积的时候做了个惊人的举动:给它个符号!
我们也这么办。
我们假设 {x,y,z⋯}n -> {x′,y′,z′⋯}m 的最小编辑距离是 N(管它怎么求的)。
跟农夫将 S 换成 S(l,w) 以体现面积和边长的关系一样,我们也将参数放进去:
N(str1, str2)
这个组合符号是说:它能算出字符串 str1转换为 str2 的最少操作步数(最小编辑距离)。
至于它怎么算的,我们暂时不关心。
这玩意是不是像极了编程中的接口?
作为程序员,你可能觉得这个 N 太丑了,那我们换个”人性化“点的名字:shortestEditDist(str1, str2)。
然后——我们盯着这奇怪的符号思考了半天,一筹莫展!
符号本身并不能告诉我们更多,我们必须开动推理的马达去加工符号。
对于集合类型问题,我们常用的一种思维模式是:看能否通过子集的解推出父集的解。
具体地,对于”串“类的问题,假如我们已经知道某个子串的解,看能否通过这个子串推出某个父串的解。
作这种解题假设的依据是:子串和父串具有相同的模式。
假设我们已经知道了 str1 中子串 [0,i] 转换成 str2 中子串 [0,j] 的最少操作步数是 M(先不管怎么算出来的),能不能求出 str1 中子串 [0,i 1] 转换成 str2 中子串 [0,j 1] 的最少操作步数?
可以吧?它其实就是在原来的基础上各加了一个字符——一个字符我们是能搞定的。
有了这个发现,我们先修正一下我们的组合符号(函数声明),将其改成:
shortestEditDist(str1, str2, i, j)
意思变成:我能求子串 str1[0,i] -> str2[0,j] 的最小编辑距离 M(管它怎么求呢,先放出大话再说)。
现在的问题变成:如何通过子串 str1[0,i] -> str2[0,j] 的最小编辑距离 M 推导子串 str1[0,i 1] -> str2[0,j 1] 的编辑距离?
我们假设 str1 的第 i 1 位的字符是 x(表示未知的某个字符),str2 的 第 j 1 位的字符是 y(另一个未知字符),如果 x 等于 y,则不用做任何操作,即最少操作步数仍然是 M;如果 x 不等于 y,则必须通过替换、删除、插入中的一种操作才能实现转换,此时最少操作步数是 M 1。
问题是,当 x 不等于 y 的时候,到底采用三种中的哪种操作呢?
三种操作的区别在于对后面字符的影响:
- 采用删除方案,则下一步要处理的是 str1 的 i 2 位置的字符和 str2 的 j 1 位置的字符(删除的意思是试图用源字符串下一个位置的字符来解决目标字符串当前位置的字符);
- 采用插入方案,下一步要处理的是 str1 的 i 1 位置的字符和 str2 的 j 2 位置的字符(插入的意思是直接在当前位置新生成目标字符串的字符,将原本该位置的字符留下来用以解决目标字符串的下一个字符);
- 采用替换方案:则是一对一抵消,下一步处理的是 str1 的 i 2 位置字符和 str2 的 j 2 位置的字符;
事实是:我们根本不知道哪种方案能使整体操作步数最少——除非一个一个尝试。
那就一个一个试吧!
我们写一下代码:
// 我能算出子串 str1[0,i] 转换为 str2[0,j] 的最小编辑距离,其中 0 <= i < n,0 <= j < m
func shortestEditDist(str1, str2 string, i, j int) int {
// 还没想好怎么实现...
}
// 求 str1 转成 str2 的最小编辑距离
func EditDistance(str1, str2 string) int {
// 既然你做了那样的声明,我就这样用
// 算不出来唯你是问!
return shortestEditDist(str1, str2, len(str1)-1, len(str2)-1);
}
既然吹了牛,终究还是要兑现它。
现在我们想想 shortestEditDist 具体怎么实现。
根据前面的思路,我们可以用 shortestEditDist(str1, str2, i-1, j-1) 来求解 shortestEditDist(str1, str2, i, j)。
// 我能算出子串 str1[0,i] 转换为 str2[0,j] 的最小编辑距离,其中 0 <= i < n,0 <= j < m
// 实现方式:用 shortestEditDist(str1, str2, i-1, j-1) 来求解 shortestEditDist(str1, str2, i, j)
// 也就是暴力递归
func shortestEditDist(str1, str2 string, i, j int) int {
// 考虑具体情况之前,先考虑递归函数的终止条件
if i == -1 && j == -1 {
// 两个都是空串,无需做任何处理
return 0
}
if j == -1 {
// str2 的子串是空串,str1 的子串[0,i] 只能采用删除操作才能转为 str2 的子串
return i 1
}
if i == -1 {
// str1 的子串是空串,此时只能采用插入操作才能转为 str2 的子串
return j 1
}
// 一般情况,根据我们前面的讨论,有四种情况
// 情况1:当前两个字符相同
if str1[i] == str2[j] {
// 两个字符相同,先将 str1[0,i-1] 转成 str2[j-1],然后本步骤啥也不做
return shortestEditDist(str1, str2, i-1, j-1)
}
// 情况2:两个字符不同,有三种情况
// 因为我们不知道本步骤到底采用什么方案才会让整体操作步数最少,所以只能都尝试一遍,然后取最小值
// 注意:我们在前面是从左往右思考问题的(往后推),而这里递归求解的方向是相反的(往前推),思维要稍微转换下
// 选择1:先用 str1[0,i-1] 转换出 str2[0,j],再删除 str1[i]
c1 := shortestEditDist(str1, str2, i-1, j) 1
// 选择2:先用 str1[0,i] 转换出 str2[0,j-1],再在后面插入 str2[j] 字符
c2 := shortestEditDist(str1, str2, i, j-1) 1
// 选择3:先用 str1[0,i-1] 转换出 str2[0,j-1],再将 str1[i] 替换成 str2[j]
c3 := shortestEditDist(str1, str2, i - 1, j - 1) 1
// 取三种情况代价最小的
return minInt(c1, c2, c3)
}
如此就求出来了。
有研究过最小编辑距离的同学可能知道最小编辑距离可以通过动态规划解决,性能更高。 本文之所以使用暴力递归,因为一方面它和动态规划的思路本质是一样的,都是递推(或说归纳法)解题。会动态规划的同学很容易将暴力递归改造成动态规划,而不会的,看递归写法要比看动态规划写法直观明白得多。
初识递归思想的同学觉得这玩意不可思议,咋在不知不觉中就把结果求出来了呢?
其实它就是我们在高中学的那个强大而陌生的数学归纳法,它要求问题具备三个特性:
- 一个集合和它的任意子集具有相同的模式;
- 可以通过子集 Sn 的解求 Sn 1 的解;
- 能够知道初始值(如 n=0)的解;
它的思想很简单:既然能够通过 Sn 的解求 Sn 1 的解,而我们又知道 S0 的解,那一定能知道 S1 的解,进而知道 S2 ......
有一点需要注意的是,我们在前面推导(递推)的时候,是通过 Sn 的解推导 Sn 1 的解(逻辑上是先考虑 Sn ),而在写递归函数的时候恰恰是反过来的:我们是先考虑 Sn 1,在处理过程中发现需要借助 Sn 来求解。而写在递归函数开头的函数终止条件恰恰就是递推(或说数学归纳法)中的初始值。
总结虽然推导矩形面积和求解字符串最小编辑距离在逻辑上存在很大差别,但在思维模式上存在很多相似性:
- 先定义清楚问题(什么是面积;什么是编辑距离);
- 用具体实例深入理解和挖掘问题(50*100 的矩形;"abcd" 和 "acdb" 两个字符串);
- 将求解对象参数化(矩形的长 l、宽 w;最小编辑距离中的 i、j);
- 将未知解符号化(面积 S;最小编辑距离 N);
- 将符号和参数组合成新的复合符号(函数。比如面积中的 S(l,w);编辑距离中的 N(str1,str2,i,j)),给问题和解建立初步的关系;
- 通过观察、试验,探求不同参数对解的影响(矩形边长加倍让面积加倍;可以用 str1[n-1] -> str2[m-1] 的解求 str1[n] -> str2[n] 的解);
- 泛化第 6 步,得出最终解;
,来源:https://www.cnblogs.com/linvanda/p/16460103.html