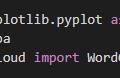
pip install jieba


jieba的分词模式
支持三种分词模式:
这里我就以昨日爬取微博鸿星尔克的评论为测试内容。
“网友:我差点以为你要*了!”鸿星尔克捐款5000w后被网友微博评论笑哭...

- 精确模式,试图将句子最精确地切开,适合文本分析;它可以将结果十分精确分开,不存在多余的词。
常用函数:cut(str)、lcut(str)
import pandas as pd
import jieba
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.cut(''.join(text))
result = ' '.join(Wordlist)
print(result)
全模式,它可以将结果全部展现,也就是一段话可以拆分进行组合的可能它都给列举出来了把句子中所有的可以成词的词语都扫描出来, 速度非常快
常用函数:lcut(str,cut_all=True) 、 cut(str,cut_all=True)
import pandas as pd
import jieba
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut(''.join(text), cut_all = True)
result = ' '.join(wordlist)
print(result)
搜索引擎模式,在精确模式的基础上,对长词再次切分它的妙处在于它可以将全模式的所有可能再次进行一个*
常用函数:lcut_for_search(str) 、cut_for_search(str)
import pandas as pd
import jieba
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
print(result)
处理停用词
在有时候我们处理大篇幅文章时,可能用不到每个词,需要将一些词过滤掉
这个时候我们需要处理掉这些词,比如我们比较熟悉的‘你’ ‘了’、 ‘我’、'的' 什么的
import pandas as pd
import jieba
from stylecloud import gen_stylecloud
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun_words = ''
# 过滤后的词
for word in result:
if word not in stop_words:
ciyun_words = word
print(ciyun_words)
可以看到,我们成功去除了我们不需要的词 ‘你’ ‘了’、 ‘我’、'的' ,那么这到底是个什么*操作呢?
其实很简单,就是将这些需要摒弃的词添加到列表中,然后我们遍历需要分词的文本,然后进行读取判断
如果遍历的文本中的某一项存在于列表中,我们便弃用它,然后将其它不包含的文本添加到字符串,这样生成的字符串就是最终的结果了。