权重分析

很多时候我们需要将关键词以出现的次数频率来排列,这个时候就需要进行权重分析了,这里提供了一个函数可以很方便我们进行分析,
jieba.analyse.extract_tagsimport pandas as pd
import jieba.analyse
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun_words = ''
for word in result:
if word not in stop_words:
ciyun_words = word
# 权重分析
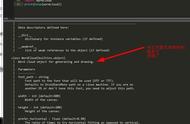
tag = jieba.analyse.extract_tags(sentence=ciyun_words, topK=10, withWeight=True)
print(tag)
'''
[('尔克', 0.529925025347557),
('国货', 0.2899827734123779),
('加油', 0.22949648081224758),
('鸿星', 0.21417335917247557),
('支持', 0.18191311638625407),
('良心', 0.09360297619470684),
('鞋子', 0.07001117869641693),
('之光', 0.06217569267289902),
('企业', 0.061882654176791535),
('直播', 0.059315225448729636)]
'''
topK就是指你想输出多少个词,withWeight指输出的词的词频。
分词介绍完了,接下来我们介绍一下绘图库
wordcloud

我们词云的主要实现是用过 wordcloud 模块中的 WordCloud 类实现的,我们先来了解一个 WordCloud 类。
安装
pip install wordcloud
生成一个简单的词云我们实现一个简单的词云的步骤如下:
导入 wordcloud 模块
准备文本数据
创建 WordCloud 对象
根据文本数据生成词云
保存词云文件