我们按照上面的步骤实现一个最简单的词云:
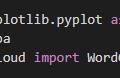
# 导入模块
from wordcloud import WordCloud
# 文本数据
text = 'he speak you most bueatiful time|Is he first meeting you'
# 词云对象
wc = WordCloud()
# 生成词云
wc.generate(text)
# 保存词云文件
wc.to_file('img.jpg')

可以看到,目标是实现了,但是效果不怎么好。我们继续往下看


WordCloud 的一些参数
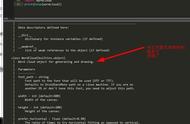
我们先看看 WordCloud 中的一些参数,
如下表,各个参数的介绍都写了。
参数 | 参数类型 | 参数介绍 |
width | int(default=400) | 词云的宽 |
height | int(default=200) | 词云的高 |
background_color | color value(default=”black”) | 词云的背景颜色 |
font_path | string | 字体路径 |
mask | nd-array(default=None) | 图云背景图片 |
stopwords | set | 要屏蔽的词语 |
maxfontsize | int(default=None) | 字体的最大大小 |
minfontsize | int(default=None) | 字体的最小大小 |
max_words | number(default=200) | 要显示词的最大个数 |
contour_width | int | 轮廓粗细 |
contour_color | color value | 轮廓颜色 |
scale | float(default=1) | 按照原先比例扩大的倍数 |
我们来测试一下上面的参数:
# 导入模块
from wordcloud import WordCloud
# 文本数据
text = 'he speak you most bueatiful time Is he first meeting you'
# 准备禁用词,需要为set类型
stopwords = set(['he', 'is'])
# 设置参数,创建WordCloud对象
wc = WordCloud(
width=200, # 设置宽为400px
height=150, # 设置高为300px
background_color='white', # 设置背景颜色为白色
stopwords=stopwords, # 设置禁用词,在生成的词云中不会出现set集合中的词
max_font_size=100, # 设置最大的字体大小,所有词都不会超过100px
min_font_size=10, # 设置最小的字体大小,所有词都不会超过10px
max_words=10, # 设置最大的单词个数
scale=2 # 扩大两倍
)
# 根据文本数据生成词云
wc.generate(text)
# 保存词云文件
wc.to_file('img.jpg')