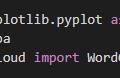
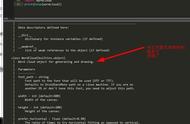
生成一个有形状的词云

我们设置的图形形状是

import pandas as pd
import jieba.analyse
from wordcloud import WordCloud
import cv2
# 读取文件
pd_data = pd.read_excel('鸿星尔克.xlsx')
# 读取内容
text = pd_data['发帖内容'].tolist()
# 切割分词
wordlist = jieba.lcut_for_search(''.join(text))
result = ' '.join(wordlist)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun_words = ''
for word in result:
if word not in stop_words:
ciyun_words = word
# 读取图片
im = cv2.imread('11.jpg')
# 设置参数,创建WordCloud对象
wc = WordCloud(
font_path='msyh.ttc', # 中文
background_color='white', # 设置背景颜色为白色
stopwords=stop_words, # 设置禁用词,在生成的词云中不会出现set集合中的词
mask=im
)
# 根据文本数据生成词云
wc.generate(ciyun_words)
# 保存词云文件
wc.to_file('img.jpg')

发现全是矩形,这是因为 WordCloud 默认不支持中文的缘故,我们需要设置一个可以支持中文的字体,我们添加代码如下:
# 创建词云对象
wc = WordCloud(font_path='msyh.ttc')