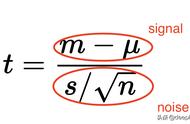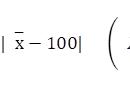统计机器学习的各种模型,都来源于最基础的线性回归。它能清晰体现出输入的变化如何导致输出的变化。
在数理统计中,回归分析是确定多种变量间相互依赖的定量关系的方法。线性回归,假设输出变量是若干输入变量的线性组合,并根据这一关系求解线性组合中的最优系数。如何评价通过线性回归得到的预测值,到底准不准确靠不靠谱呢?可以通过均方误差的大小来评价。
均方误差在训练集上确定系数 wi 时,预测输出 f(x) 和真实输出 y 之间的误差是评价模型训练程度的核心指标。在线性回归中,这一误差是以均方误差来定义的。
均方误差(Mean Squared Error,MSE)是一种用于衡量预测值与真实值之间差异的指标。它是在回归问题中经常使用的一种损失函数。均方误差计算了预测值与真实值之间差异的平方的平均值。
由于均方误差计算了预测误差的平方,并取平均值,因此它对较大的误差更为敏感。这也意味着如果有一个极大的误差,它将对均方误差有较大的影响。在机器学习中,优化算法的目标通常是最小化均方误差,即找到能够使预测值与真实值之间的差异平方和最小的模型参数。
最小二乘法使均方误差取得最小值为目标的模型求解方法就是最小二乘法。在单变量线性回归任务中,最小二乘法的作用就是找到一条直线,使所有样本到直线的欧几里得距离之和最小。线性回归的数学表达式可以写成:
其中n为维度数,而非样本数。假设其样本数为N,通常N会远大于n。
标准误差采用最小二乘法求解线性回归问题,得到的解即为线性回归数学表达式中,参数的估计值。当使用最小二乘法进行参数估计时,估计值的期望值等于真实参数值。这是因为在最小二乘法中,通过最小化均方误差,我们得到的估计值是对观测数据与模型预测值之间的误差的“平均”估计。由于残差的期望为零,最小二乘法的估计值也具有无偏性。虽然具有无偏性,但每一个特定的估计值结果依然会在真实值的附近波动,标准误差度量的就是估计值偏离真实值的平均程度。
标准误差的计算是为了量化回归模型的拟合程度,并提供一个衡量模型预测误差的指标。标准误差越小,表示模型对数据的拟合越好。其数值上等于均方误差的平方根。
置信区间是对一个参数的估计提供一个范围,该范围内有一定的置信水平(如90%、95%、99%等)包含了真实的参数值。换句话说,置信区间是用来表示我们对参数估计的不确定性程度的一种统计区间。举个例子:如何计算置信区间的上下界?计算公式如下:
临界值通常使用 t 分布或者标准正态分布的临界值来确定。什么情况下适合使用t分布,什么情况适合使用标准正态分布?选择使用 t 分布还是标准正态分布取决于样本量的大小以及对总体方差的了解程度。
使用 t 分布的情况:
- 当样本量较小(一般小于30)时,t 分布更适用。在小样本情况下,由于对总体方差的估计受到样本大小的限制,使用 t 分布能够更准确地考虑到不确定性。
- 当总体方差未知时,而使用样本标准差作为估计时,也应使用 t 分布。这是因为使用样本标准差估计总体标准差引入了额外的不确定性,而 t 分布考虑了这种不确定性。
使用标准正态分布的情况:
- 当样本量较大时,尤其是当样本量大于30时,中心极限定理使得样本均值的分布近似于正态分布。在这种情况下,可以使用标准正态分布的临界值进行置信区间的计算,而不会引入较大的误差。
- 当总体方差已知时,也可以使用标准正态分布。这通常是在实际应用中相对少见的情况,因为总体方差通常是未知的。
t统计量(t-statistic)是用于在统计学中进行假设检验或计算置信区间的一种统计量。它通常用于比较样本均值与总体均值之间的差异,并考虑样本的大小和标准误差。
t统计量的一般形式为:
其中:
- 是样本均值。
- μ 是总体均值的假设值。
- s 是样本标准差。
- n 是样本大小。
这个统计量的计算涉及对样本均值与总体均值之间差异的标准化,考虑到了样本大小和样本标准差。计算得到的t统计量用于比较观察到的样本均值与预期的总体均值之间的差异,以及对差异的显著性进行统计推断。
在线性回归中通常会假设待拟合的参数值为 0,此时的 t 统计量就等于估计值除以标准误。当数据中的噪声满足正态分布时,t 统计量就满足 t 分布,其绝对值越大意味着参数等于 0 的可能性越小,拟合的结果也就越可信。
p值是一种用于判断假设检验结果的指标。它表示观察到的样本数据在零假设成立的情况下,出现与之相符或更极端的情况的概率。简单地说,p 值表示的是数据与一个给定模型不匹配的程度,p 值越小,说明数据和原假设的模型越不匹配,也就和计算出的模型越匹配。
具体来说,p值可以被解释为在假设零假设为真的情况下,观察到的样本统计量(比如t统计量、z统计量等)的概率。p值的大小反映了我们拒绝零假设的程度:
- 如果p值很小,通常小于一个事先设定的显著性水平(通常为0.05),我们有足够的证据来拒绝零假设,认为观察到的效应是显著的。
- 如果p值较大,大于显著性水平,我们没有足够的证据拒绝零假设,认为观察到的效应不是显著的。
在进行假设检验时,通常会设定一个显著性水平(例如0.05),如果p值小于这个水平,我们就拒绝零假设,认为我们观察到的效应是显著的。如果p值大于显著性水平,我们不拒绝零假设,认为我们没有足够的证据支持替代假设。
p值如何计算?
计算p值的具体方法取决于所进行的假设检验以及统计模型的类型。下面介绍两种常见的情况:t检验和z检验。
t检验的p值计算:
- 对于单样本t检验,可计算出t统计量。
- 根据t统计量和自由度,查找t分布表或使用统计软件计算p值。
z检验的p值计算:
- 对于z检验,计算z统计量:
- 其中,是样本均值,μ0是零假设的均值,σ是总体标准差,n是样本大小。
- 根据z统计量,查找标准正态分布表或使用统计软件计算p值。
R-squared(R²),也称为决定系数,是用于度量线性回归模型拟合优度的统计量。它提供了一个衡量因变量的变异程度被模型解释的程度。
R-squared的取值范围在0到1之间,表示因变量方差的百分比,可以被模型解释的程度。具体地说,R-squared表示因变量变异的百分比,该变异可以由模型中的自变量解释。例如,R-squared值为0.75表示75%的因变量方差可以由模型解释,而剩余的25%则不能被模型解释,通常被认为是由于未考虑的因素或纯粹的随机性。
R-squared的计算公式为:
其中,残差平方和是观测值与模型预测值之间的差异的平方的总和,总平方和是观测值与观测值均值之间的差异的平方的总和。R-squared越接近1,表示模型对数据的拟合越好;越接近0,表示模型对数据的拟合越差。
需要注意的是,R-squared值不能衡量模型的预测能力或因果关系,它只是衡量模型对训练数据的拟合程度。在实际应用中,为了全面评估模型,还需要考虑其他指标和实际问题的背景。
还有一种校正决定系数是什么?,即Adj. R-squared:
调整的 R-squared(Adj. R-squared)是 R-squared 的一种校正版本,用于修正由于模型中自变量数量增加而导致 R-squared 增加的情况。Adj. R-squared 提供了更准确的模型拟合优度的度量,特别是在增加自变量时,防止过度拟合的问题。
Adj. R-squared 的计算公式为:
其中,
- R2 是普通的 R-squared 统计量。
- n 是样本大小(观测值的数量)。
- k 是模型中的自变量数量。
与 R-squared 不同,Adj. R-squared 在计算中考虑了自变量的数量 �k 和样本大小 �n。因此,当模型中增加自变量时,Adj. R-squared 会根据样本大小和自变量数量进行调整,避免因增加自变量而导致 R-squared 增加而不准确地认为模型拟合得更好。
在实际应用中,Adj. R-squared 更适合用于比较不同模型的拟合优度,特别是在考虑模型复杂性的情况下。然而,就像任何统计量一样,它也应该与其他评估指标一起使用,以全面评估模型性能。
F统计量输出的因变量只与单个的输入自变量存在线性关系,这种模型被称为简单线性回归。但更一般的情况是因变量由多个自变量共同决定,对这些自变量同时建模就是多元线性回归。对多远线性回归使用最小二乘进行分析后,可能会得到校正决定系数和 p 值给出自相矛盾的解释,这时就需要观察另外一个重要的指标:F 统计量。
- 在线性回归中,F统计量用于评估整个回归模型的拟合优度,即检验回归模型是否显著。
- 计算公式为:
- 回归平方和表示因变量的变异能够由模型解释的部分,残差平方和表示模型无法解释的部分。F统计量越大,说明模型整体的拟合效果相对较好。
当因变量数量变多时,多元线性回归就会遇到一个无法回避的问题:模型虽然具有足够的精确性,却缺乏关于精确性的合理解释。
小结我是以机器学习的角度,来回顾线性回归所涉及的统计学概念。所以更多的是关注这些对于模型求解所得指标的评价,而其背后所涉及的统计学概念,请容我暂时不求甚解了。对这些统计学概念的推导与解释感兴趣的话,需得空闲找一本详尽的统计学教材翻越,此处推荐《普林斯顿概率论读本》、《统计至简》、《概率导论》。后续篇幅将聚焦于机器学习的模型理解,统计学若有所得,我想应该是另起主题记录。
,